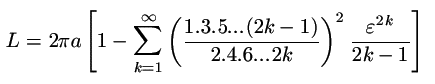- dir [ls -l]
- mkdir
- copy [cp]
- move [mv]
- del [rm]
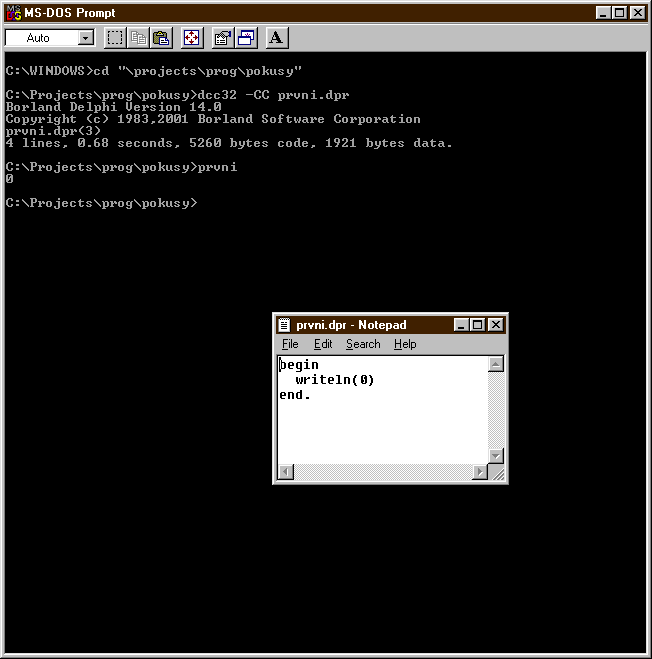
- dcc32 -CC prvni.dpr [gpc
prvni.pas]
- notepad [nedit]








Návod pro klikoše
Windows umožňují asociovat s příponou souboru nějaký program. Dvojité (obvykle) kliknutí na nějaký soubor pak tento asociovaný program spustí a tento program pak vhodně použijevámi odkliknutý soubor. Podobně se chovaní i Delphi(R). Máme-li tedy již vytvořený soubor "prvni.dpr", stačí na něj kliknout a začnou se dít věci.
Bohužel, nyní musíme vývojovému
prostředí Delphi vysvětlit, že jsme začátečníci a budeme psát jednouché
programy s textovým a nikoli grafickým vstupem a výstupem.
Nejdříve klikneme pravým (tím neobvyklým)
tlačítkem myši vedle 1 cm napravo vedle nápisu Help
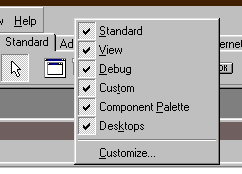
a zrušíme fajfku u položky "Component
Pallete".
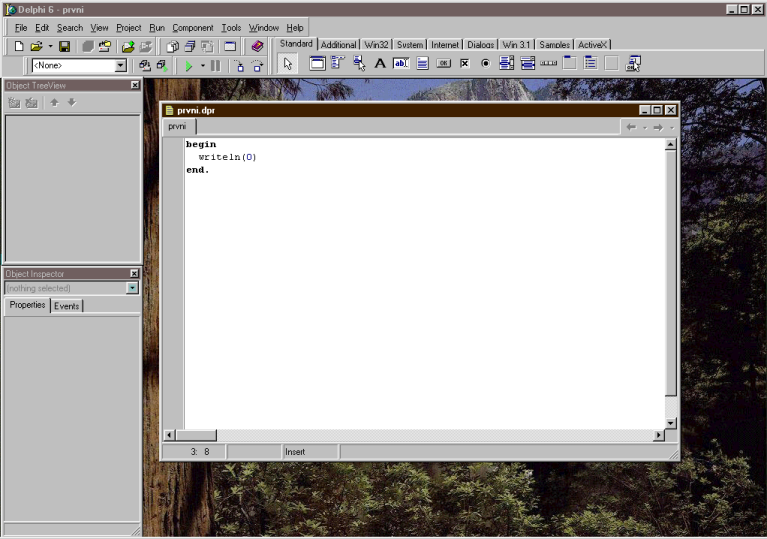
Poté kliknutím na křížek zavřeme obě malá okna
nalevo a podle vašeho vkusu i zvětšíme okno s naším programem
"prvni.dpr". Estéti ještě mohou myší přenést panýlky nástrojů z třetí
řady počítáno svrchu za jejich levý okraj o řádek či dva výše. Poté
naše pracovní plocha vypadá takhle:
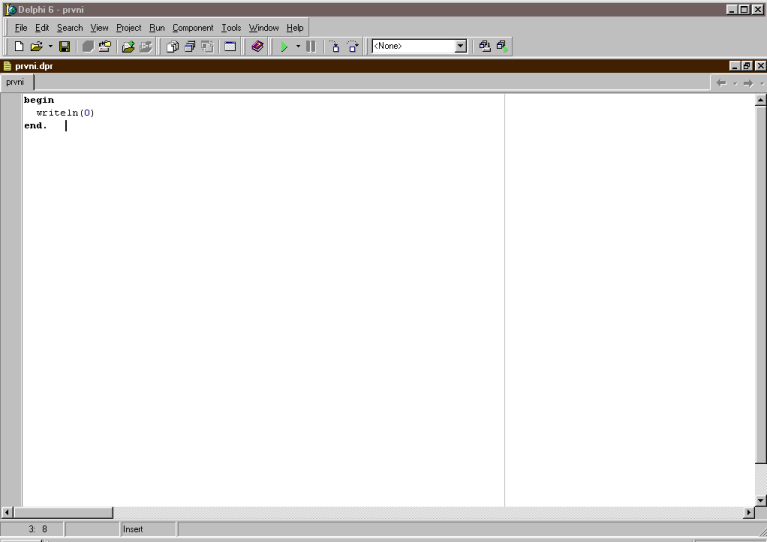
Nyní klikneme na čudlík vedle nápisu
"None" a na dotaz odpovíme třeba takto:
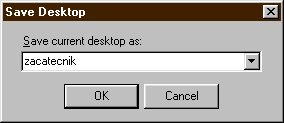
Nyní můžeme celé vývojové prostředí Delphi zavřít a vyzkoušet si, že při příští aktivaci souboru prvni.dpr (a vlastně i druhy.dpr, pokud si takový mezitím nějak vytvoříme) se vše obnoví v tomto začátečnickém rozložení pracovní plochy.
Nyní je již jen potřeba v menu pod
položkou Project/Options nebo (současným) stisknutím klávesové zkratky
Control-Shif-F11 aktivovat menu nastavemní a v něm zvolit záložku LINKER.
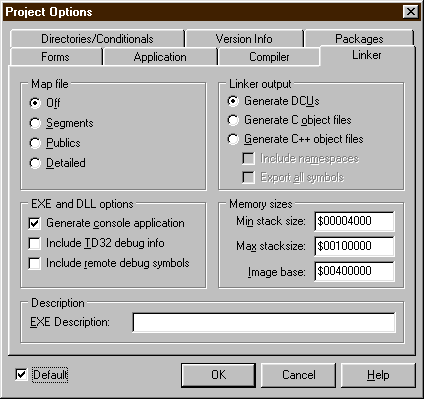
Zde musíme zaškrtnout dvě fajfky:
Tímto jsme jedné z částí překladače oznámili, že budeme psát programy určené k běhu v okně příkazového řádku, "konsoli".
Tím jsme hotovi.
Nezapoměňte, že běh programu je obvyle velmi rychlý a pokud si chceme výsledky prohlédnout, musíme na poslední řádek programu napsat kouzelné slůvko:
readln;
Začneme kolejištěm pro pascalovksý program:
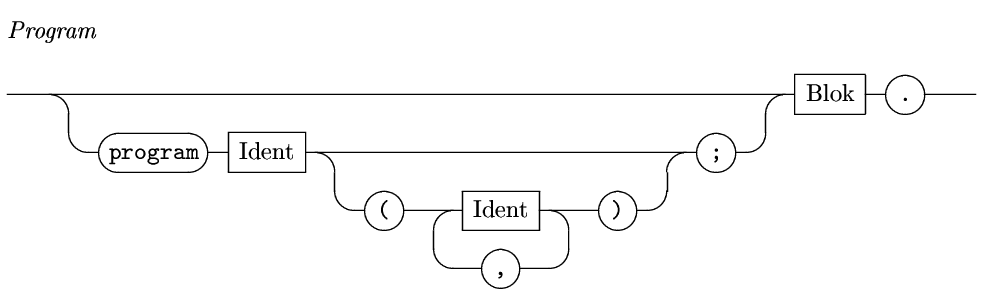
Protože je uvozovací část nepovinná, je správně jak následující program
program SHlavickou;tak i tento kratký
begin
writeln('Jsem spravny program!');
end.
begin writeln('Jsem usporny program!') end.
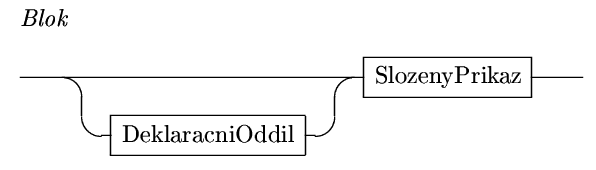
Předchozí programy byly těmi
nejjednoduššími, jaké si lze představit. Neobsahují
žádnou deklaraci a ten druhý se skládá pouze
ze složeného příkazu. Tento složený příkaz
ale bývá předcházen deklaračním
oddílem, který jak později uvidíme, tvoří
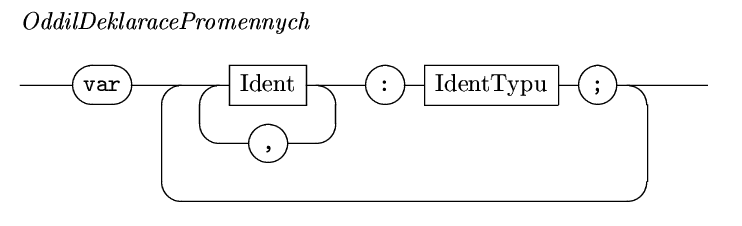
těžiště struktrurovaného programu.V naší zatím velmi zjednodušené verzi Pascalu budeme uvažovat pouze proměnnéakonstanty a tak deklarační oddíl popisuje následující "kolejiště":
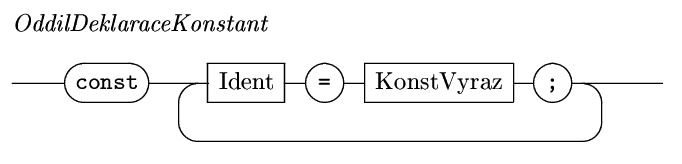
Konstanty jsou zkratky za konstantní výrazy. Existují dobré důvody proč používat konstanty:
const HorniMez = 12;Proměnné představují místa pro uložení hodnoty, jak později uvidíme, ne nezbytně numerické povahy.
EulerovaKonst = 0.577215664901532861;
program SKonstantouADvemaPromennymi;Tento velmi jednoduchý program nám kromě důvodů pro použití konstant ilustruje i použití složeného příkazu, který tvoří nejen závěrečnou (výkonnou) část pascalovského bloku, ale také umožňuje v cyklu while vykonávat více jak jeden příkaz:
const N = 10;
var i,s : integer;
begin
i:=1;
s:=0;
while i<=N do
begin
s:=s+i;
i:=i+1;
end;
writeln('Soucet cisel od 1 do ',N,' je ',s);
end.
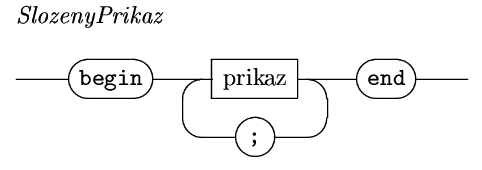
Jak jsme viděli, program se
skládá z hlavičky, deklarací a složeného
příkazu, což je sekvence příkazů oddělená
středníky a uzavřená mezi slova begin a end a tečky za programem.

Za prvé, jak vidíme, nic (prázdný příkaz) je také příkaz.
Jednoduché příkazy jsou v podstatě dva, strukturovaných příkazů je více, mezi ty základní patří samotný složený příkaz, podmíněný příkaz a příkazy cyklu.

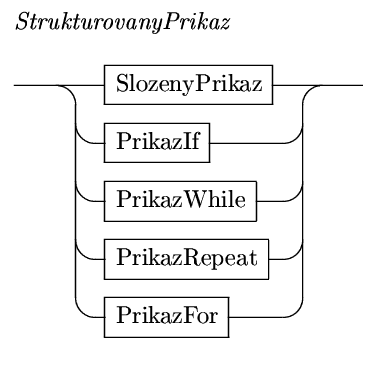
Jednoduché příkazy
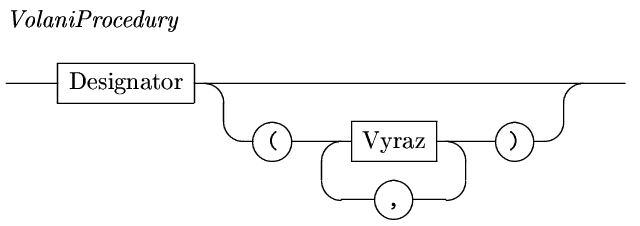
Ještě nejméně týden pro nás
bude designátor totožný s identifikátorem,
až se dozvíme, že jsou i další prvky jazyka, hodí
se vědět, kde jazyk vyžaduje identifikátor, a kde můžeme
použít "něco obecnějšího".
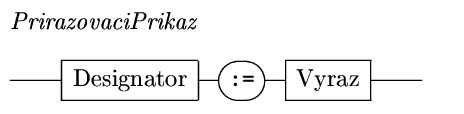
Obě uvedené formy jednoduchého
příkazu ilustrují následjující dva
řádky:
c := (a+b)/2;Strukturované příkazy - Podmíněný příkaz
Writeln( 'Prumer cisel ',a,' a ',b,' je ',c);
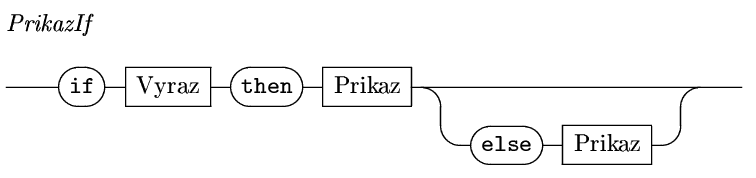
má dvě varinaty. Krátkou (if ...
then ... )
if a<b then a:=b;a dlouhou (if ... then ... else ...)
if b*b-4*a*c>=0 then writeln('Rovnice ma reseni')
else writeln('Rovnice nema reseni');
Problém je, že není
úplně zřejmé, zda je správně tato
if a>0 thennebo naopak tato indentace
if b>0 then c:=1
else c:=2;
if a>0 thenPodle pravidla, že v syntaktických diagramech opuštíme dosaženou úroveň až když musíme, je správně druhá verse. Abychom dosáhli účinku zamýšleného indentací prvního příkladu, musíme psát
if b>0 then c:=1
else c:=2;
if a>0 thenPřípadně můžeme použít prázdný příkaz
begin
if b>0 then c:=1
end
else c:=2;
if a>0 then
if b>0 then c:=1
else
else c:=2;
Cyklus While
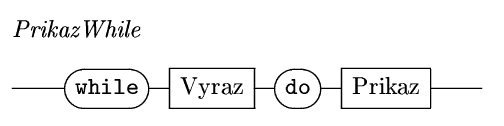
nejdříve se vyhodnotí
podmínka a je-li splněna (hodnota true), provedede se
příkaz, pak se znovu vyhodnotí podmínka atd.
Nesplnění podmínky znamená konec
provádění tohoto strukturovaného příkazu. V
příkazu následujícím za přikazem while
tak mohu předpokládat, že Vyraz má hodnotu
nepravda (false).
Cyklus Repeat
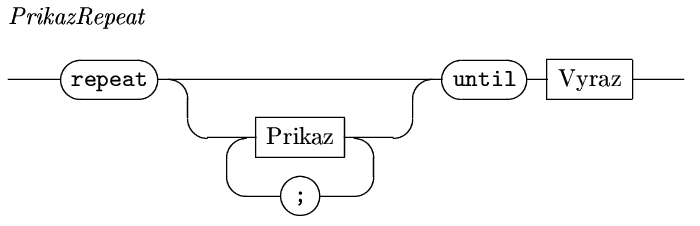
nejdříve se vykonají všechny
příkazy mezi klíčovými slovy repeat a until
a pokud následně podmínka není splněna (Vyraz
má hodnotu false), opakuje se provádění
příkazů v cyklu atd. V příkazu
následujícím za příkazem repeat tak
mohu předpokládat, že Vyraz má hodnotu pravda (true).
repeatje tedy rovnocenný příkazům
writeln(i);
i:=i+1;
until i>10;
writeln(i);
i:=i+1;
while i<=10 do begin
writeln(i);
i:=i+1;
end;
Cyklus For
Je určen jako zkratka cyklu while v
případě, kdy potřebujeme projít všecha celá
čísla v nějakém intervalu

a umožní nám zjednodušit
náš sčítací program
program SKonstantouDvemaPromennymiACyklemFor;Příkaz for je zkratkou cyklu while a tak při nevhodné konstalaci mezí nemusí být příkaz ani jednou vykonán.
const N = 10;
var i,s : integer;
begin
s:=0; {na tohle nesmím zapomenout}
for i:=1 to N do s:=s+i;
writeln('Soucet cisel od 1 do ',N,' je ',s);
end.
Příklad: následující program nám odhalí, kteráže trojciferná čísla jsou stejně jako třeba číslo 153 součtem třetích mocnin svých cifer.
program cisla;Pozn.: Algoritmus, který tento program popisuje, patří do třídy těch nejpotupnějších, neboť jej lze zapsat slovy: zkus všechny možnosti. (Slang: Brute force) Bohužel v diskrétních úlohách někdy ani lepší nenajdeme. Naštěstí není celých čísel "tak moc" jako těch reálných.
var a,i,j,k:integer;
begin
for i:=1 to 9 do {např. 024 není trojciferné, tak začínám od 1}
for j:=0 to 9 do
for k:=0 to 9 do
begin
a:=i*100+j*10+k;
if a=i*i*i+j*j*j+k*k*k then writeln(a);
end;
end.
Výrazy
V předcházejících příkladech programů jsme používali m.j. přiřazovací příkaz a ten má na pravé straně výraz. Jde o přirozené zobecnění matematické notace do formy textu "vytisknutelného na dálnopise", zůstávají pojmy operand, operace, priorita.
Především, operace "porovnání" (>,
<, <=, ...) jsou v Pascalu operátory s nějnižší prioritou. V
syntaktickém diagramu to vypadá takhle:
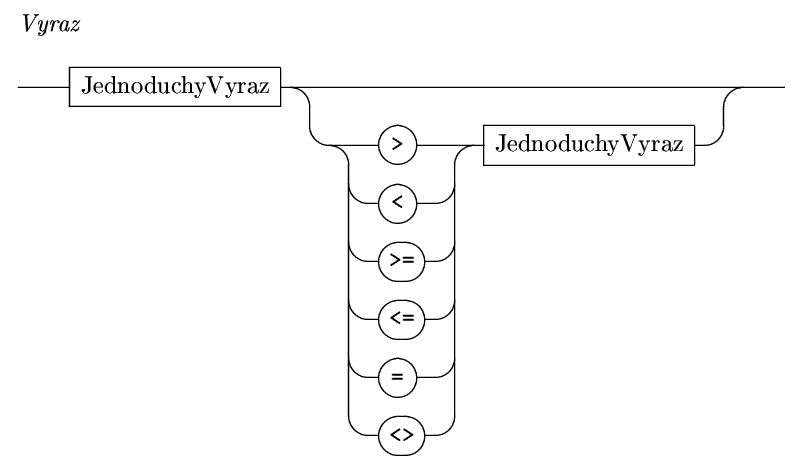
Teď přichází na řadu obvyklé sčítání,
odčítání a analogické logické operace
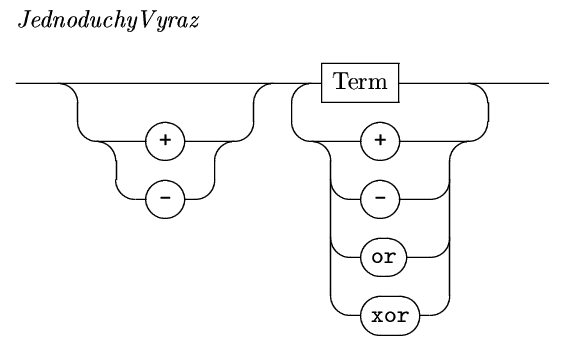
Termy, tedy sčítance mohou být
součinem, podílem atp. jednotlivých faktorů.
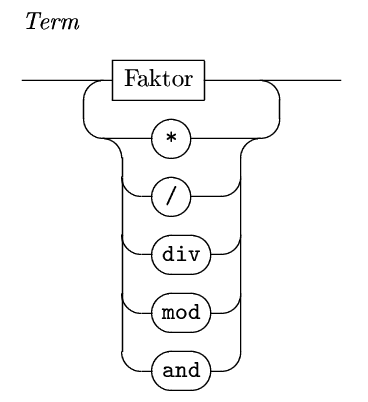
Zde je třeba upozornit na operaci
zbytku celočíselného dělení mod:
program CislaII;
var a,i,j,k:integer;
begin
for a:=100 to 999 do begin
i := a div 100; {stovky}
j := (a div 10) mod 10; {desitky}
{j := (a mod 100) div 10; }
k := a mod 10; {jednotky}
if a=i*i*i+j*j*j+k*k*k then writeln(a);
end;
end.
program EuklidII;
var a,b :integer;
begin
a := 11088;
b := 17017;
while a<>b do
if a>b then a:=(a-1) mod b + 1
else b:=(b-1) mod a + 1;
writeln(a);
end.
program EuklidIII;No a konečně každý faktor může být identifikátor proměnné či konstanty, číslo atp.
var a,b,c :integer;
begin
a := 11088;
b := 17017;
repeat
c := a mod b;
a := b;
b := c; {vyznam: (a,b) := (b,a mod b) }
until b=0;
writeln(a);
end.
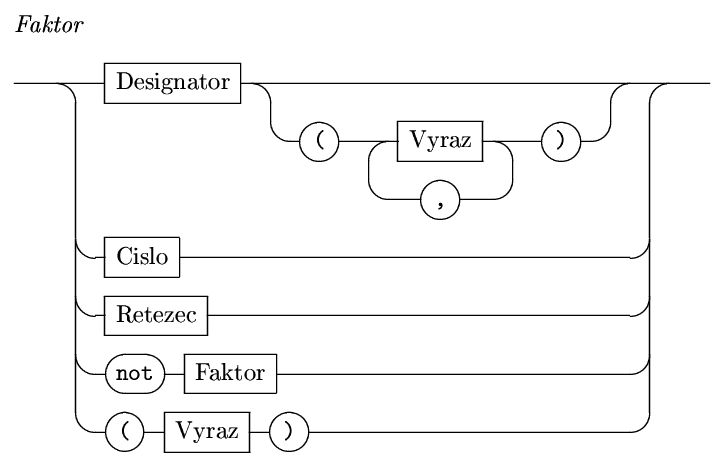
Nejříve si připomeňme, že designátor
je prozatím totéž, co identifikátor. První řádek (horní kolej) pak říká,
že pravé strany následujících přiřazovacích příkazů jsou správné faktory,
tedy i termy, tedy i jednoduché výrazy a konečně tedy i
správné výrazy:
s:=a;
y:=sin(x);
b:=InRange(y,-1,1);
Jak víme ne každý syntakticky správný kus kódu
nám překladač schválí, třeba
var a:integer;není správný program. Identifikátor před závorkou totiž musí být identifikátor funkce. To že deklarujeme proměnnou či konstantu vlastně znamená, že uvedenému identifikátoru přiřadíme význam. Některé identifikátory jsou však definovány "samy od sebe". Mezi ně patrí i tzv. standardní funkce. Zde jen seznam některých z nich:
begin
a:=a(1);
end.
Následující funkce vrací reálnou
hodnotu
ArcTan arkustangens
Cos
cosinus
Sin sinus
Exp exponenciála
Ln přirozený
logaritmus
Sqrt druhá
odmocnina
Int
celá část čísla
Round nejbližší
celé číslo
Protože druhá mocnina celého čísla je
vždy celé číslo,
je typ výsledku volání funkce sqr dán
typem parametru.
Sqr druhá
mocina
Logické operátory
Typ boolean popisuje logický stav ano/ne, v řeči Pascalu true/false.
Jakkoli se interně reprezentují hodnota false jako 0 a hodnota
true jako 1 jsou v jazyce Pascal logické hodnoty svým typem izolovány od
celých čísel a běžné aritmetické oprece pro ně nejsou definovány. Proto
nelze psát
k := (i=imax) + (j=jmax);
( umožní nám to v budoucnu operace/funkce ord ).
Nad hodnotami false a true však pracují logické operátory:
1. Binární operátory: and, or, xor
| and | false | true |
| false | false | false |
| true | false | true |
| or | false | true |
| false | false | true |
| true | true | true |
| xor | false | true |
| false | false | true |
| true | true | false |
2. Unární operátor negace not:
| not | false | true |
| true | false |
Relační operátory (=, <>, <, <=, >, >=)
Porovnávají dvě hodnoty, přičemž podobně jako + či * umějí porovnat
reálné a celé číslo (přesněji dva jednoduché výrazy těchto typů).
Navíc také umějí porovnat logické hodnoty ve smyslu
false < true.
Ve všech případech je výsledkem porovnání logická (boolean) hodnota.
Celá čísla v počítači
V současné době je standardem používat k uložení celého čísla 32 bitů. Protože je to docela dlouhé dvojkové číslo, použijeme pro následující příklad pouze čtyři bity.
Ilustrace
Do čtyřech bitů lze uložit následujících 16 kombinací 0 a 1:
3210 hex unsigned signed
---- - -------- ------
0000 0 0 0
0001 1 1 1
0010 2 2 2
0011 3 3 3
0100 4 4 4
0101 5 5 5
0110 6 6 6
0111 7 7 7
1000 8 8 -8
1001 9 9 -7
1010 A 10 -6
1011 B 11 -5
1100 C 12 -4
1101 D 13 -3
1110 E 14 -2
1111 F 15 -1
Když potřebujeme do 4-bitového čísla uložit číslo s významem celého
čísla se znaménkem máme několik možností. V posledním slupci tabulky je
uveden dnes nejrozšířenější způsob - reprezentace celého čísla se
znaménkem pomocí tzv. dvojkového doplňku. Je to technologicky nejméně
nákladný způsob jak obvody počítače naučit pracovat zárověň s
čísly se znaménkem i bez znaménka. To proto, že stroj nemusí rozlišovat,
zda sčítá či odčítá číslo se znaménkem nebo bez:
Operace 1010+0010 = 1100 má podle okolností buď význam
10 + 2 = 12
a nebo
-6 + 2 = -4.
Protože pomocí 4 bitů můžeme reprezentovat čísla 0..15 resp -8..7 vedou některé operace k tzv. přetečení.
Pro čísla bez znaménka je to např. operace 15+15, jejíž
výsledek neleží v intervalu 0..15.
Pokud se natuto operaci díváme z pohledu operací se znaménkem, je vše
O.K., neboť (-2)+(-2)=-4.
Pro čísla se znaménkem je nedovolená např. operace 4+4=8, neboť jako horní mez rozsahu čtyřbitových oznaménovaných čísel je 7. Z hlediska čísel bez naménka je to ovšem operace dovolená.
Pro nás znamená typ integer 32 bitové číslo se znaménkem povolující
uložení celého čísla v rozsahu –2 147 483 648 ..
2 147 483 647.
V případě, že nějaká oprace, např. v příkazu k:=i*j vede k
přetečení, není obvykle spuštěn žádný poplach a program se posléze chová
podivně bez zjevných příčin, protože výsledek přiřazovacího příkazu je
jiný, než zamýšlený. Je ale možné donutit program, aby si tato možná
přetečení ohlídal, stráví se tím nějaký čas navíc, ale ušetří to čas při
hledání problémů. Až se budeme zabývat laděním programů bude zapnutí
kontroly na přetečení jedním z bodů v návodu.
Ve vyjímečných případech budeme potřebovat vědět, že jsou k dispozici i jiné celočíselné typy:
Identif.Typu Rozsah Formát uložení
-----------------------------------------------
Shortint –128..127 signed 8-bit
Smallint –32768..32767 signed 16-bit
Longint –2147483648..2147483647 signed 32-bit
Int64 –2^63..2^63–1 signed 64-bit
Byte 0..255 unsigned 8-bit
Word 0..65535 unsigned 16-bit
Longword 0..4294967295 unsigned 32-bit
Jak vidíme, typ Integer je v současné době totožný s typem Longint. Je pravděpodobné, že během několika let bude typ Integer odpovídat 64-bitovému číslu a neměli bychom spoléhat na to, že proměnné typu Integer jsou ukládány jako zrovna jako 32-bitové. Abychom však nemuseli hlídat každý součin 200*200 (nevejde se do SmallInt), budeme předpokládat, že těch bitů je nejméně 32, takže pozor na přetečení si budeme muset dávat až u součinů jako je 50000*50000.
S výjimkou typu Int64 obecně neplatí, že operace s kratším formátem
je rychlejší, takže důvody pro použití kratšího formátu čísla musí být v
algoritmu samém, ne jeho optimalizaci. Jednou z výjimek je úspora paměti
při uložení miliónů a miliónů celých čísel v poli (viz dále), převážným
důvodem ale bude respektování formátu vstupních dat: např. komponenty
RGB v bitmapě jsou typu Byte, zvuk v audiosouboru na kompaktním disku
je zase posloupnost dvojic (L,R) oznaménkovaných 16-bitových čísel (
typ SmallInt ).
Aritmetické operátory a typy
Cím se liší následující výrazy?
1*1
1/1
1>1
Především výraz (1>1) nemá hodnotu číselnou ale logickou.
Protože lomítko je symbolem pro reálné dělení, je výsledek podílu 1/1
"reálná jednička", zatímco u součinu je ta jednička celé číslo.
Operandy +-*/ mohou být čísla realná nebo celá, div a mod
mají jako operandy pouze čísla celá.
Za předpokladu, že proměnné x,y,i a j jsou deklarovány takto:
var i,j : integer;
x,y : real;
můžeme aritmetické oprace shrnout v následující tabulce
| význam | operand | výsledek | příklad--> typ výsledku | |
| + | sčítání | real, integer | real,integer | x+i --> real |
| - | odčítání | real,integer | real,integer | i-j --> integer |
| * | násobení | real,integer | real,integer | x*y --> real |
| / | reálné dělení | real,integer | real | i/j --> real |
| div | celočíselné dělení | integer | integer | i div j --> integer |
| mod | zbytek při dělení | integer | integer | i mod j --> integer |
Pro oparace +-* platí, že výsledek je celé číslo pouze pokud jsou oba operandy celá čísla.
Hodnota celočíselného podílu
i div j
je rovna hdonotě reálného podílu zaokrouhlené směrem k nule, tedy
i div j = trunc(i/j)
Pro záporná i a/nebo j je tato definice kompatibilní se vztahy
(-i)/j = - (i/j), i/(-j) = - (i/j)
Operace mod splňuje vztah
i mod j = i – (i div j) * j
Obvukle ji budme používat pouze pro j>0 a i>=0, kdy platí že
i mod j = 0..j-1
tedy jde o běžnou operaci zbytku po dělení a např.
17 mod 5 = 2 .
Pokud je j=0, způsobí operace
x / j
i div j
i mod j
krach programu.
Unární oprátory + - nemění typ.
Logické operace nad celými čísly
Z technických důvodů se čísla v počítači uskladňují ve dvojkovém
zápisu. Na jednotlivé bity lze pak aplikovat logické operátory and, or,
xor a not ve stejném smyslu jako pro true a false.
var x,y : Integer;
....
x := 21;
y := 12;
{ nyní platí }
x or y = 29
{ neboť
00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
or 00000000 00000000 00000000 00001100 // 12 = 0+8+4+0+0
----------------------------------------------------------
00000000 00000000 00000000 00011101 // 29 = 16+8+4+0+1 }
x and y = 4
{ neboť
00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
and 00000000 00000000 00000000 00001100 // 12 = 0+8+4+0+0
----------------------------------------------------------
00000000 00000000 00000000 00000100 // 4 = 0+0+4+0+0 }
x xor y = 25
{ neboť
00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
xor 00000000 00000000 00000000 00001100 // 12 = 0+8+4+0+0
----------------------------------------------------------
00000000 00000000 00000000 00011001 // 25 = 16+8+0+0+1 }
not x = -22
{ neboť
not 00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
---------------------------------------------------------------
11111111 11111111 11111111 11101010 //-22 = (-1)-16-0-4-0-1 }
Mimochodem, aby si programátoři šetřili klávesy 0 a 1, místo binárního
zápisu používají zápis šestnáctkový (hexadecimální). čtveřice bitů se
podle výše uvedené tabulky ozačí číslicí 0..9 nebo písmenem A-F. Proto
nám následující příkaz writeln vypíše TRUE:
writeln( not $15 = $FFFFFFEA );
Protože Wirth nepoužil znak $ ve své versi Pascalu, mohl být později
použit $ jako uvozovací znak při zápisu šestnáctkového čísla a výše
uvedený kód je správně.
Protože jde jen o zápis čísla pro kompilátor, a $15 je naprosto totéž
jako 21, zkuste uhodnout co udělá následující příkaz:
writeln( $15 );
Rady do života: Celá a reálná čísla
V jazyce Pascal se přes jeho přísnou kotrolu typů povoluje použít
celé číslo na místě reálného. Proto do reálné proměnné smíme
dosadit hodnotu s typem Integer, přesněji v přiřazovacím příkazu
idProm:=Vyraz
kde idProm je identifikátor reálné proměnné smí mít Vyraz
nejen reálný typ ale i typ celočíselný.
Ačkoili tedy nepředstavuje současné použití celých a reálných čísel v Pascalu problém, je v případě podílu dvou celých čísel na místě naučit se dávat si pozor. V příkazu
E := 1/2*m*v*v;
se podíl 1/2 vyhodnotí na konstantu 0.5 a příkaz provede, co jsme zamýšleli. Protože však např. v jazycích FORTRAN a C se podíl 1/2 vyhodnotí jako 0 a do E se dosadí nula, je pro budoucího fyzika vhodné zvyknout si psát např.
V := 4/3.0*Pi*r*r*r;
a nebo 4.0/3 atp. Nejjednodušší je nezvyknout, abychom si pak
nemuseli odvykat.
Podobně bychom si neměli zvykat jako celočíselné ukládat hodnoty
typu n! nebo 2^n neboť
ani v 32-bitových celých číslech na ně není "dost místa".
Řešení problémů hrubou silou
Jako první při řešení nějakého problému uvažujeme algoritmus
spočívající v použití hrubé síly.
Jako ilustraci tohot přístupu uvažujme následující program, který hledá
všechny neuspořádané trojice kladných čísel, které leží na kouli o
poloměru 2003, pokud je chápeme jako kartézské souřadnice bodu v
prostoru a koule má střed v počátku.
Načtněme nejdříve obrysy takového postupu:
program Rozklady1;
var a,b,c,N :integer;
begin
N:=2003;
Writeln('Rozklady cisla ',N);
{pro vsechny trojice N>a>=b>=c>0 zkoumej zda plati}
for a:=1 to N-1 do
for b:=1 to a do
for c:=1 to b do
begin
if a*a+b*b+c*c=N*N then writeln(a,' ',b,' ',c);
end;
Writeln('konec');
end.
Následující variantu je stále možné považovat za použití hrubé síly, i když je cca 60x rychlejší.
program Rozklady2;
var a,b,c,N :integer;
begin
N:=2003;
Writeln('Rozklady cisla ',N);
{pro vhodne trojice N>a>=b>=c>0 zkoumej zda plati}
for a:=1 to N-1 do
begin
b:=1;
while (b<=a) and (N*N-a*a-b*b>0) do
begin
c:=trunc(0.5+sqrt(N*N-a*a-b*b));
if (c<=b) and (a*a+b*b+c*c=N*N) then writeln(a,' ',b,' ',c);
b:=b+1;
end;
end;
Writeln('konec');
end.
Navíc se následujícími příkazy můžeme přesvědčit, že oba programy dávají stejné výsledky. Zde použijeme trik s přesměrováním výstupu programu do souboru (To je to znaménko > mezi příkazem a názvem výstupního souboru). Necháme tak vytvořit dva soubory, jejichž názvy si samozřejmě můžeme zvolit libovolně, a posléze jejich obsah porovnáme. Práci s porovnáváním obsahu můžeme přenechat počítači, pokud si zjistíme, který program to za nás udělá. Seznam takovýchto užitečných programů dodám později, a pak se dozvíte, že v tomto případě je třeba použít program s názvem FC (pro příkazový řádek MS Windows).
C:\Projects\prog\pokusy>Rozklady1 > Vysledky1.txt |
Příkládky k přemýšlení
1. Jaké jsou typy následujících výrazů? Jsou všechny zapsány správně?
{deklarace}
var i,j,k : integer;
x,y,z : real;
be : boolean;
{ nyní následují výrazy }
i+j
i*j
i/j
i+y
i*y
i/y
i mod y
be and i>j
i>j and x>y
be or not 2*be
2. Zapište jako přiřazovací příkazy následující vzorečky (volbu
identifikátorů a počet přiřazení je na vás)
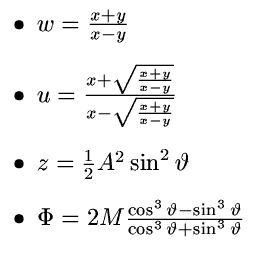
3. Doplňte do následujícího kódu správný výraz místo ?????
const N = 54354;
var i,j,k,pocetprocent: Integer;
begin
{...}
for i:=1 to N do
begin
{zkoumej moznost i}
{...}
{uz jsem to prozkoumal, ted to jeste oznamim obsluze, ktera ceka na vysledek}
pocetprocent := ????? ;
Write('Prave jsem prozkoumal ',pocetprocent,'% moznych hodnot. ',#13);
end;
{...}
end.
Po správném doplnění otazníků můžete program použít jak je. Psaní
hlášení o postupu výpočtu zabere programu tolik času, že vlastně ani
není potřeba aby něco užitečného dělal a i tak poběží pár sekund.
Vyzkoušejte !
Vyzkoumejte, co to je ten #13 !!! Třeba tak, že jej nejprve odstraníte,
poté nahradíte třeba #33 a uvidíte ten rozdíl.
4. Všichni znáte součtové vzorce, zvažte následující kód:
const k=100;
alpha=0;
beta=0.1;
var sa,ca,sb,cb,soucet : real;
n:integer;
begin
{do promennych sa a ca strcim sin prip cos alpha:}
sa := sin(alpha);
ca := cos(alpha);
{do promennych sb a cb strcim sin prip cos beta:}
sb := sin(beta);
cb := cos(beta);
{ nyni mohu spocitat
soucet := sin(alpha)+sin(alpha+beta)+sin(alpha+2*beta)+...+sin(alpha+N*beta) ,
kdyz vyuziji souctovych vzorcu takto:}
soucet:=sa;
for n:=1 to k do begin
sa := sa*cb+ca*sb;
ca := ca*cb-sa*sb;
soucet := soucet + sa;
end;
{...}
writeln(soucet);
end.
Co je na tomhle kódu špatně? Přesněji, kde je v cyklu chyba, která
způsobí, že nedostanu součet sinů? Opravte tu chybu.
Lekce 3
Aritmetické operátory a typy
Cím se liší následující výrazy?
1*1
1/1
1>1
Především výraz (1>1) nemá hodnotu číselnou ale logickou.
Protože lomítko je symbolem pro reálné dělení, je výsledek podílu 1/1
"reálná jednička", zatímco u součinu je ta jednička celé číslo.
Operandy +-*/ mohou být čísla realná nebo celá, div a mod
mají jako operandy pouze čísla celá.
Za předpokladu, že proměnné x,y,i a j jsou deklarovány takto:
var i,j : integer;
x,y : real;
můžeme aritmetické oprace shrnout v následující tabulce
| význam | operand | výsledek | příklad--> typ výsledku | |
| + | sčítání | real, integer | real,integer | x+i --> real |
| - | odčítání | real,integer | real,integer | i-j --> integer |
| * | násobení | real,integer | real,integer | x*y --> real |
| / | reálné dělení | real,integer | real | i/j --> real |
| div | celočíselné dělení | integer | integer | i div j --> integer |
| mod | zbytek při dělení | integer | integer | i mod j --> integer |
Pro oparace +-* platí, že výsledek je celé číslo pouze pokud jsou oba operandy celá čísla.
Hodnota celočíselného podílu
i div j
je rovna hdonotě reálného podílu zaokrouhlené směrem k nule, tedy
i div j = trunc(i/j)
Pro záporná i a/nebo j je tato definice kompatibilní se vztahy
(-i)/j = - (i/j), i/(-j) = - (i/j)
Operace mod splňuje vztah
i mod j = i – (i div j) * j
Obvukle ji budme používat pouze pro j>0 a i>=0, kdy platí že
i mod j = 0..j-1
tedy jde o běžnou operaci zbytku po dělení a např.
17 mod 5 = 2 .
Pokud je j=0, způsobí operace
x / j
i div j
i mod j
krach programu.
Unární oprátory + - nemění typ.
Logické operátory
Typ boolean popisuje logický stav ano/ne, v řeči Pascalu true/false.
Jakkoli se interně reprezentují hodnota false jako 0 a hodnota
true jako 1 jsou v jazyce Pascal logické hodnoty svým typem izolovány od
celých čísel a běžné aritmetické oprece pro ně nejsou definovány. Proto
nelze psát
k := (i=imax) + (j=jmax);
( umožní nám to v budoucnu operace/funkce ord ).
Nad hodnotami false a true však pracují logické operátory:
1. Binární operátory: and, or, xor
| and | false | true |
| false | false | false |
| true | false | true |
| or | false | true |
| false | false | true |
| true | true | true |
| xor | false | true |
| false | false | true |
| true | true | false |
2. Unární operátor negace not:
| not | false | true |
| true | false |
Relační operátory (=, <>, <, <=, >, >=)
Porovnávají dvě hodnoty, přičemž podobně jako + či * umějí porovnat
reálné a celé číslo (přesněji dva jednoduché výrazy těchto typů).
Navíc také umějí porovnat logické hodnoty ve smyslu
false < true.
Ve všech případech je výsledkem porovnání logická (boolean) hodnota.
Celá čísla v počítači
V současné době je standardem používat k uložení celého čísla 32 bitů. Protože je to docela dlouhé dvojkové číslo, použijeme pro následující příklad pouze čtyři bity.
Ilustrace
Do čtyřech bitů lze uložit následujících 16 kombinací 0 a 1:
3210 hex unsigned signed
---- - -------- ------
0000 0 0 0
0001 1 1 1
0010 2 2 2
0011 3 3 3
0100 4 4 4
0101 5 5 5
0110 6 6 6
0111 7 7 7
1000 8 8 -8
1001 9 9 -7
1010 A 10 -6
1011 B 11 -5
1100 C 12 -4
1101 D 13 -3
1110 E 14 -2
1111 F 15 -1
Když potřebujeme do 4-bitového čísla uložit číslo s významem celého
čísla se znaménkem máme několik možností. V posledním slupci tabulky je
uveden dnes nejrozšířenější způsob - reprezentace celého čísla se
znaménkem pomocí tzv. dvojkového doplňku. Je to technologicky nejméně
nákladný způsob jak obvody počítače naučit pracovat zárověň s
čísly se znaménkem i bez znaménka. To proto, že stroj nemusí rozlišovat,
zda sčítá či odčítá číslo se znaménkem nebo bez:
Operace 1010+0010 = 1100 má podle okolností buď význam
10 + 2 = 12
a nebo
-6 + 2 = -4.
Protože pomocí 4 bitů můžeme reprezentovat čísla 0..15 resp -8..7 vedou některé operace k tzv. přetečení.
Pro čísla bez znaménka je to např. operace 15+15, jejíž
výsledek neleží v intervalu 0..15.
Pokud se natuto operaci díváme z pohledu operací se znaménkem, je vše
O.K., neboť (-2)+(-2)=-4.
Pro čísla se znaménkem je nedovolená např. operace 4+4=8, neboť jako horní mez rozsahu čtyřbitových oznaménovaných čísel je 7. Z hlediska čísel bez naménka je to ovšem operace dovolená.
Pro nás znamená typ integer 32 bitové číslo se znaménkem povolující
uložení celého čísla v rozsahu –2 147 483 648 ..
2 147 483 647.
V případě, že nějaká oprace, např. v příkazu k:=i*j vede k
přetečení, není obvykle spuštěn žádný poplach a program se posléze chová
podivně bez zjevných příčin, protože výsledek přiřazovacího příkazu je
jiný, než zamýšlený. Je ale možné donutit program, aby si tato možná
přetečení ohlídal, stráví se tím nějaký čas navíc, ale ušetří to čas
při hledání problémů. Až se budeme zabývat laděním programů bude
zapnutí kontroly na přetečení jedním z bodů v návodu.
Ve vyjímečných případech budeme potřebovat vědět, že jsou k dispozici i jiné celočíselné typy:
Identif.Typu Rozsah Formát uložení
-----------------------------------------------
Shortint –128..127 signed 8-bit
Smallint –32768..32767 signed 16-bit
Longint –2147483648..2147483647 signed 32-bit
Int64 –2^63..2^63–1 signed 64-bit
Byte 0..255 unsigned 8-bit
Word 0..65535 unsigned 16-bit
Longword 0..4294967295 unsigned 32-bit
Jak vidíme, typ Integer je v současné době totožný s typem Longint. Je pravděpodobné, že během několika let bude typ Integer odpovídat 64-bitovému číslu a neměli bychom spoléhat na to, že proměnné typu Integer jsou ukládány jako zrovna jako 32-bitové. Abychom však nemuseli hlídat každý součin 200*200 (nevejde se do SmallInt), budeme předpokládat, že těch bitů je nejméně 32, takže pozor na přetečení si budeme muset dávat až u součinů jako je 50000*50000.
S výjimkou typu Int64 obecně neplatí, že operace s kratším formátem
je rychlejší, takže důvody pro použití kratšího formátu čísla musí být v
algoritmu samém, ne jeho optimalizaci. Jednou z výjimek je úspora
paměti při uložení miliónů a miliónů celých čísel v poli (viz dále),
převážným důvodem ale bude respektování formátu vstupních dat: např.
komponenty RGB v bitmapě jsou typu Byte, zvuk v audiosouboru na
kompaktním disku je zase posloupnost dvojic (L,R) oznaménkovaných
16-bitových čísel ( typ SmallInt ).
Logické operace nad celými čísly
Z technických důvodů se čísla v počítači uskladňují ve dvojkovém
zápisu. Na jednotlivé bity lze pak aplikovat logické operátory and, or,
xor a not ve stejném smyslu jako pro true a false.
var x,y : Integer;
....
x := 21;
y := 12;
{ nyní platí }
x or y = 29
{ neboť
00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
or 00000000 00000000 00000000 00001100 // 12 = 0+8+4+0+0
----------------------------------------------------------
00000000 00000000 00000000 00011101 // 29 = 16+8+4+0+1 }
x and y = 4
{ neboť
00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
and 00000000 00000000 00000000 00001100 // 12 = 0+8+4+0+0
----------------------------------------------------------
00000000 00000000 00000000 00000100 // 4 = 0+0+4+0+0 }
x xor y = 25
{ neboť
00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
xor 00000000 00000000 00000000 00001100 // 12 = 0+8+4+0+0
----------------------------------------------------------
00000000 00000000 00000000 00011001 // 25 = 16+8+0+0+1 }
not x = -22
{ neboť
not 00000000 00000000 00000000 00010101 // 21 = 16+0+4+0+1
---------------------------------------------------------------
11111111 11111111 11111111 11101010 //-22 = (-1)-16-0-4-0-1 }
Mimochodem, aby si programátoři šetřili klávesy 0 a 1, místo binárního
zápisu používají zápis šestnáctkový (hexadecimální). čtveřice bitů se
podle výše uvedené tabulky ozačí číslicí 0..9 nebo písmenem A-F. Proto
nám následující příkaz writeln vypíše TRUE:
writeln( not $15 = $FFFFFFEA );
Protože Wirth nepoužil znak $ ve své versi Pascalu, mohl být později
použit $ jako uvozovací znak při zápisu šestnáctkového čísla a výše
uvedený kód je správně.
Protože jde jen o zápis čísla pro kompilátor, a $15 je naprosto totéž
jako 21, zkuste uhodnout co udělá následující příkaz:
writeln( $15 );
Celá a reálná čísla
V jazyce Pascal se přes jeho přísnou kotrolu typů povoluje použít
celé číslo na místě reálného. Proto do reálné proměnné smíme
dosadit hodnotu s typem Integer, přesněji v přiřazovacím příkazu
idProm:=Vyraz
kde idProm je identifikátor reálné proměnné smí mít Vyraz
nejen reálný typ ale i typ celočíselný.
Zvláštním případem je podíl dvou celých čísel. V příkazu
E := 1/2*m*v*v;
se podíl 1/2 vyhodnotí na konstantu 0.5 a příkaz provede, co jsme zamýšleli. Protože však např. v jazycích FORTRAN a C se podíl 1/2 vyhodnotí jako 0 a do E se dosadí nula, je pro budoucího fyzika vhdoné zvyknout si psát např.
V := 4/3.0*Pi*r*r*r;
a nebo 4.0/3 atp.
Řešení problémů hrubou silou
Jako první při řešení nějakého problému uvažujeme algoritmus
spočívající v použití hrubé síly.
Jako ilustraci tohot přístupu uvažujme následující program, který hledá
všechny neuspořádané trojice kladných čísel, které leží na kouli o
poloměru 2003, pokud je chápeme jako kartézské souřadnice bodu v
prostoru a koule má střed v počátku.
Načtněme nejdříve obrysy takového postupu:
program Rozklady1;
var a,b,c,N :integer;
begin
N:=2003;
Writeln('Rozklady cisla ',N);
{pro vsechny trojice N>a>=b>=c>0 zkoumej zda plati}
for a:=1 to N-1 do
for b:=1 to a do
for c:=1 to b do
begin
if a*a+b*b+c*c=N*N then writeln(a,' ',b,' ',c);
end;
Writeln('konec');
end.
Následující variantu je stále možné považovat za použití hrubé síly, i když je cca 60x rychlejší.
program Rozklady2;
var a,b,c,N :integer;
begin
N:=2003;
Writeln('Rozklady cisla ',N);
{pro vhodne trojice N>a>=b>=c>0 zkoumej zda plati}
for a:=1 to N-1 do
begin
b:=1;
while (b<=a) and (N*N-a*a-b*b>0) do
begin
c:=trunc(0.5+sqrt(N*N-a*a-b*b));
if (c<=b) and (a*a+b*b+c*c=N*N) then writeln(a,' ',b,' ',c);
b:=b+1;
end;
end;
Writeln('konec');
end.
Navíc se následujícími příkazy můžeme přesvědčit, že oba programy dávají stejné výsledky. Zde použijeme trik s přesměrováním výstupu programu do souboru (To je to znaménko > mezi příkazem a názvem výstupního souboru). Necháme tak vytvořit dva soubory, jejichž názvy si samozřejmě můžeme zvolit libovolně, a posléze jejich obsah porovnáme. Práci s porovnáváním obsahu můžeme přenechat počítači, pokud si zjistíme, který program to za nás udělá. Seznam takovýchto užitečných programů dodám později, a pak se dozvíte, že v tomto případě je třeba použít program s názvem FC (pro příkazový řádek MS Windows).
C:\Projects\prog\pokusy>Rozklady1 > Vysledky1.txt |
Příkládky k přemýšlení
1. Jaké jsou typy následujících výrazů? Jsou všechny zapsány správně?
{deklarace}
var i,j,k : integer;
x,y,z : real;
be : boolean;
{ nyní následují výrazy }
i+j
i*j
i/j
i+y
i*y
i/y
i mod y
be and i>j
i>j and x>y
be or not 2*be
2. Zapište jako přiřazovací příkazy následující vzorečky (volbu
identifikátorů a počet přiřazení je na vás)
3. Doplňte do následujícího kódu správný výraz místo ?????
const N = 54354;
var i,j,k,pocetprocent: Integer;
begin
{...}
for i:=1 to N do
begin
{zkoumej moznost i}
{...}
{uz jsem to prozkoumal, ted to jeste oznamim obsluze, ktera ceka na vysledek}
pocetprocent := ????? ;
Write('Prave jsem prozkoumal ',pocetprocent,'% moznych hodnot. ',#13);
end;
{...}
end.
Po správném doplnění otazníků můžete program použít jak je. Psaní
hlášení o postupu výpočtu zabere programu tolik času, že vlastně ani
není potřeba aby něco užitečného dělal a i tak poběží pár sekund.
Vyzkoušejte !
Vyzkoumejte, co to je ten #13 !!! Třeba tak, že jej nejprve odstraníte,
poté nahradíte třeba #33 a uvidíte ten rozdíl.
4. Všichni znáte součtové vzorce, zvažte následující kód:
const k=100;
alpha=0;
beta=0.1;
var sa,ca,sb,cb,soucet : real;
n:integer;
begin
{do promennych sa a ca strcim sin prip cos alpha:}
sa := sin(alpha);
ca := cos(alpha);
{do promennych sb a cb strcim sin prip cos beta:}
sb := sin(beta);
cb := cos(beta);
{ nyni mohu spocitat
soucet := sin(alpha+beta)+sin(alpha+2*beta)+...+sin(alpha+N*beta) ,
kdyz vyuziji souctovych vzorcu takto:}
soucet:=sa;
for n:=1 to k do begin
sa := sa*cb+ca*sb;
ca := ca*cb-sa*sb;
soucet := soucet + sa;
end;
{...}
writeln(soucet);
end.
Co je na tomhle kódu špatně? Přesněji, kde je v cyklu chyba, která
způsobí, že nedostanu součet sinů? Opravte tu chybu.
Pravidla a dokumentace
Procedury a funkce tvoří nejdůležitější prvek, který používáme při členění programu. Je dobré, když při jejich psaní dodržujeme jistá pravidla. Především u funkce či procedury rozlišujeme:Čím je kód programu vzdálenější našemu jazyku, tím větší je pravděpodobnost, že při psaní kódu programu uděláme chybu. Platí to i u intelektuálně nenáročných kusů kódu: Při psaní
y := ln(x + sqrt(x*x + 1))
ještě nejspíš chybu neuděláme, i když zápis
y := ArcSinh(x)
je přehlednější a mnohem odolnější vůči chybě. Pokud budeme chtít spočíst
z := ArcSinh(sqrt((x-1)/(x+1)))
roste pravděpodobnost, že se při přepisu do tvaru
z := ln( sqrt( (x-1)/(x+1) ) + sqrt( 2*x/(x+1) ) )
dopustíme chyby.
Pododbně jako výpočet nějaké funkce může nějaká posloupnost příkazů tvořit jasný celek, který je pak pro přehlednost možné vyjmout z místa, kde jej chceme uplatnit a vytvořit z něj Proceduru.
Satrapa [Sa] píše:
Kdykoli si řeknete "teď by se mi hodilo aby pascal měl příkaz (nebo funkci), který ....", vymyslete si vhodné jméno a obohaťte Pascal o nový příkaz (či funkci) - definujte podprogram.
Uvidíme, že budou případy, kdy to takto jednoduše nepůjde, ale jako motto je to výstižné.
I když jsme se vzdali představy, že o budeme dokazovat správnost programu, nepochybně chceme psát správné programy. Vytvořením vhodné hierarchie krátkých přehledných podprogramů, lze i ideálním případě na každé úrovni dosáhnout toho, že na každé úrovni je podprogram očividně správně.
Ovšemže by měl být zmíněn také hlavní a každému zřejmý důvod zavední procedur a fukcí: V případě, kdy bych byl nucen opakovat již jednou napsaný kus kódu, nabízí se tu možnost ulehčit si práci se psaním. Protože jsme ze školy zvyklí myslet "strukturovaně", oba důvody pro použití funkcí (a procedur) se překrývají: Kód se opakuje, protože representuje nějaký podproblém.
Euklidův algoritmus jako funkceJako příklad budiž zmíněn opět Euklidův algoritmus. Co kdybychom chtěli spočíst nějvětší společný dělitel tří čísel? Jak? Co takhle spočíst NSD třetího čísla a NSD prvních dvou čísel? ..... Pak by zřejmě nebylo od věci moci zapsat celý postup třeba takto:
vysledek := GCD( c, GCD(a,b) );Aby nám překladač rozumněl, musíme mu oznámit, že
V jazyce Pascal se to provede tak, že v deklaracích bloku, ve kterém
chceme tuhle funkci použít, spolu s proměnnými a konstantami,
deklarujeme ještě fukci.
function GCD(a,b : integer) : integer;Časem si nakreslíme syntaktický diagram, ale i bez něj rozpoznáváme jasnou strukturu Hlavička-Deklarace-Složený Příkaz, jakou má pascalský program. Z kódu je jasně vidět, že použití identifikátorů a,b se neodlišuje od použití identifikátoru proměnné c. Na rozdíl od proměnných mají ale a a b na začátku přiřazené hodnoty. Pokud bychom funkci GCD použili například takto:
var c:integer;
begin
repeat
c := a mod b;
a := b;
b := c; { (a,b) := (b,a mod b); }
until b=0;
GCD := a;
end; {function GCD}
n := GCD(44,55) ;bude na začátku provádění příkazů těla funkce mít a hodnotu 44 a b hodnotu 55. Proměnná c bude mít hodnotu nedefinovanou. Proto její hodnota nesmí být užita dříve, než jí bude nějaká přiřazena.
Takto pak vypadá celý kód programu:
program GCD3;
const a = 26112;
b = 75548;
c = 45288;
var n : integer;
function GCD(a,b : integer):integer;
{Vrací NSD dvou kladných čísel}
var c:integer;
begin
if (a<=0) or (b<=0) then {oznam chybu a skonci}
begin
Writeln('Funkce GCD(', a, ',', b, ') : Neplatne parametry!');
Halt;
end;
repeat
c := a mod b;
a := b;
b := c;
until b=0;
GCD := a;
end; {konec deklarce funkce GCD}
begin
n := GCD( a, GCD(b,c) ) ;
Writeln('Nejvetsi spolecny delitel cisel ', a,' ',b,' ',c,' je ',n,' nebot:');
Writeln(a,' = ',a div n,'*',n);
Writeln(b,' = ',b div n,'*',n);
Writeln(c,' = ',c div n,'*',n);
Readln;
end.
program P;Otázka pak zní zda se program přeloží do kódu
function f(a:real):real;
begin
f:=sin(a)
end;
begin
writeln(f(1));
writeln(f(2));
end.
nebo do kódu
VezmiKonstantu 1.0
SpočtiSinus
VypišHodnotu
VezmiKonstantu 2.0
SpočtiSinus
VypišHodnotu
Skonči
VezmiKonstantu 1.0Vidíme že druhá varianta je v tomto případě delší, ale tušíme, že pokud by funkce f byla komplikovanější, zabraly by její dvě(či ještě více) kopie více místa než vyžaduje varianta druhá. Tušíme, že první varianta (hantýrka: macro nebo též inline) je výhodná pouze pro extrémně krátké funkce a běžně se stává, že ji kompilátory vůbec nepodporují. Měli bychom tedy vědět, že funkce a procedury se překládají jako samostatné kusy programu a jejich kód je uložen i velmi daleko od místa, kde se používají.
ZavolejFunkci f
VypišHodnotu
VezmiKonstantu 2.0
ZavolejFunkci f
VypišHodnotu
Skonči
TadyJeFunkce f:
VyzvedniPředanouHodnotu
SpočtiSinus
VraťSe
Procedury jako nástroj strukturovaného programování
Procedury na rozdíl od funkcí, nevracejí hodnotu, přesněji nepoužíváme je ke konstrukci výrazů, ale jsou to příkazy. Pomáhají nám, aby naše programy mohly být složeny z přehledných částí. Třeba takto:
Program VylepsovacZvuku;
.....
begin
NactiAudiosoubor;
OpravPraskani;
SnizSumeni;
ZapisAudiosoubor;
end.
Teď už jen zbývá napsat ty čtyři procedury. Každou z nich napíšeme jako
posloupnost dostatečně jednoduchých operací, a pokud nebudou v nabídce
jazyka Pascal, vymyslíme vhodný identifikátor nové procedury, která tuto
složitou operaci zařídí a tuto posléze stejným postupem rozepíšeme jako
posloupnost ještě jednodušších příkazů. Takže psát programy je
jednoduché, že.
Toto je velmi zhruba idea psaní program shora dolů. Je dobré ji mít
na paměti, když program píšeme, jakkoli nám nebude při psaní programu
vždy pasovat na naši úlohu. V každém případě stála u kolébky globální
struktury jazyka Pascal jak uvidíme v následujícím:
Připomeňme si nejprve syntaktický diagram pro program:
A takto vypadají diagramy pro proceduru a funkci
Jak vidíme jsou procedury složeny kromě hlavičky opět z bloku a v
něm můžeme kromě proměnných a konstant deklarovat i opět další
procedury a tak by náš program mohl vypadat takto:
Program VylepsovacZvuku;
...
Procedure OpravPraskani;
...
Procedure OdectiPoruchu;
...
begin
...
end;
...
begin
...
OdectiPoruchu;
...
end;
...
begin
...
OpravPraskani;
...
end.
Procedura OdectiPoduchu se nachází uvnitř jiné procedury a ne programu,
říkáme, že je to vnořená procedura (funkce). Upozornění: vnořené
procedury (a funkce) nejsou v některých běžných programovacích jazycích
podporovány, takže pokud si na ně příliš zvykneme hrozí nám dalším
životě riziko, že si budeme muset odvykat.
Přesněji bychom měli mluvit o identifikátorech, protože v deklarační
části procedury a funkce můžeme deklarovat cokoli, co můžeme deklarovat
v bloku programu, proměnné jsou ale tím nejdůležitějším.
Abychom mohli používat podprogramy, je třeba vyjasnit které identifikátory platí uvnitř kterého bloku. Veměme třeba
program KdoKdyKde;Když někde v bloku deklarujeme identifikátor, zůstává v platnosti až do konce tohoto bloku. Může však být zakryt deklarací uvnitř bloku nějaké funkce či procedury. To je případ identifikátorů i a s uvnitř funkce f v příkladu výše. Naopak, proměnná N je viditelná i uvnitř funkce f (není ničím zastíněna), čehož využíváme. Proměnné deklarované v bloku programu naýváme globální, ty deklarované v bloku procedury či funkce nazýváme lokální.
var N,i,s:integer;
function f(a:integer):integer;
var i,s:integer; {co kdyz tenhle radek zakomentujeme ?}
begin
s:=0;
for i:=1 to N do s:=s+sqr(a+i);
f:=s;
end;
begin
N:=10;
s:=0;
for i:=1 to N do s:=s+f(i);
writeln(s);
readln;
end.
program ProcSGlobProm;
var i;
procedure MojeProc;
begin
i:=0;
end;
begin
i:=1;
Writeln(i);
MojeProc;
Writeln(i);
end.
program ProcSParHodnotou;V tomto případě mi program vypíše dvě jedničky. Procedura se dozví jakou hodnotu mělo i, ale dále pracuje jen s touto hodnotou. Proměnné b přísluší vlastní chlívek v paměti a jeho modifikací se nemění hodnota chlívku i.
var i;
procedure MojeProc(b:integer);
begin
b:=0;
end;
begin
i:=1;
Writeln(i);
MojeProc(i);
Writeln(i);
end.
program ProcSParOdkazem;V tomto případě mi program vypíše jedničku a nulu. Procedura se dozví kde je uskladněna proměnná i, a dále pracuje s tímto odkazem, tedy s proměnnou samou. Předání parametru odkazem zařídí, že chlívek s názvem i se uvnitř procedury jmenuje ještě též b.
var i;
procedure MojeProc(var b:integer);
begin
b:=0;
end;
begin
i:=1;
Writeln(i);
MojeProc(i);
Writeln(i);
end.
function NactiSeznam(var Sz : typSeznam; JakDlouhy : integer) : boolean;
begin
....
....
NactiSenznam := NacenaDelka = JakDlouhy;
end;
Malujeme funkci
Naše znalosti nám začínají umožňovat psát užitečné programy a díky možnosti dát programu strukturu můžeme jednou nalezená řešení znovu použít.
Nejdříve si ukažme, jak můžeme namalovat graf funkce.
program MalujFci;
const xa = 0;
xb = 1;
N = 100;
function MalovanaFce(x:real):real;
begin MalovanaFce := x*exp(x) end;
var x,y : real;
i : integer;
begin for i := 0 to N do begin x := xa + (xb-xa)*i/N; y := MalovanaFce(x); writeln(x,' ',y); end;
end.
Především si všimněme, že zde je malovaná funkce izolovaná do zvláštní funkce a příkazy těla programu se výpočtem funkční hodnoty nezabývají. Sice jsme si tím program trochu zkomplikovali, ale až budeme chtít malovat jinou funkci, bude nám identifikátor funkce připomínat, kde je třeba program změnit.
I při letmém prohlédnutí kódu ovšem okamžite vidíme, ze program nic nemaluje, pouze vypíše tabulku skládající se ze dvou sloupečků oddělených mezerou. V prvním je hodnota nezávislé proměnné, ve druhém funkční hodnota. Proč se tedy tady mluví o malování fukce?
Pokud bychom měli "namalováním grafu funkce" na mysli zobrazení grafu na obrazovce počítače a posléze toho i dosáhli, brzy bychom došli k názoru, že si ten obrázek ještě chceme uložit. Po chvíli bychom pak pak zjistili, že nejmenší omezení pro budoucí práci s obrázkem dosáhneme, pokud si poznamenáme funkční hodnoty namalované funkce pro případ, že bychom si chtěli prohlédnout detailní chování funkce v okolí nějakého bodu nebo místo lineárního zvolit logaritmické škálování os, atp. Proto si necháváme otevřené všechny moznosti, a jednoduše vypisujeme pouze funkční hodnoty.
Aby data jentak "nezmizela" za horním okrajem okénka konsole, provedeme trik, který jsme jiz použili: přesměrujeme výstup programu do souboru. Možná si ješte pamatujete, že se to dělá tak, že na příkazové řádce kromě spuštení programu požádáme též o přesměrování uvedením znaku '>' a názvu souboru:
C:\Projects\prog\pokusy>MalujFci > graf1.dat
To ale znamená, že budme potřebovat něco, co nám z hodot
uložených v souboru graf1.dat udělá obrázek. Na počítaci
se takové něco nazývá obecně program a jak to s programem
bývá není nad to, když uz někdo takový program napsal a
dovolí nám ho používat.
Malujeme funkci - GNUPLOT
Pro naše potřeby bude ideální program s názvem gnuplot (a jak nám napovídají první písmena názvu, nebudeme za něj muset nic platit). Uživatel ovládá gnuplot prostrednictvím príkazů. Například soubor, který se skládá ze dvou sloupců čísel vykreslíme jako graf funkce tak, že zadáme příkaz
plot "graf1.dat"
bouhužel takto ješte nezískáme, co chceme, protože nám vyleze graf složený z puntíků.
Proto budeme chtít program přesvedčit, aby maloval data ze souboru pomocí čar. Máme dvě moznosti. Buď k příkazu plot přidáme na konec "with lines", tedy
plot "graf1.dat" with lines
nebo změníme nastavení pomocí příkazu set a pak uz můžeme jen poroučet plot, plot, ....
set data style lines
plot "graf1.dat"
K jednou zadanému příkazu se můžeme vracet pomocí kláves [nahoru] a [dolu], takze se nemusíme opakovaně obtěžovat s vypisováním názvu datového souboru.
Budeme-li chtít vykreslit do jednoho grafu data ze dvou souborů jendoduše názvy souboru v úvozovkách oddělíme čárkou
plot "graf1.dat", "graf2.dat"
Konečně, pokud má soubor tvar tří (nebo více) sloupečků čísel, můžeme nechat vymalovat nejdřív první versus druhý sloupec hodnot a poté první versus třetí sloupec následujícím příkazem:
plot "graf2.dat", "graf2.dat" using 1:3
jak je vidět, using 1:2 jsme psát nemuseli, to se rozumí samo sebou.
Program gnuplot si podle rozsahu malovaných hodnot sám určí v jakém rozsahu se mají oškálovat osy. Pokud ale chceme některou z takto určených hodnot změnit, můžeme hned za slovo plot přidat meze v hranatých závorkách oddělené dvojtečkou. Vyzkoušejte, co udělají následující příkazy:
plot [0.2:0.5] "graf1.dat"
plot [:0.5] "graf1.dat"
plot [0.2:] "graf1.dat"
plot [][0:10] "graf1.dat"
plot [0.2:][:10] "graf1.dat"
Časem budeme potřebovat vědět, že pokud v datovém souboru vynecháme prázdný řádek, chápe gnuplot následující data jako novou křivku, pokud vynecháme dva prázdné řádky, chápe data jako rozdělená na sekce, přičemž můžeme s jednotlivými sekcemi pracovat zvlášť pomocí slova index.To použijeme později, taď jen je dobré vědět, že když potřebujeme znát správné použití třeba slova index, napíšeme: help index. Dále je dobré vědět, že až budeme potřebovat obrázek začlenit do nějakého článku, nabídne nám gnuplot možnost vytvořit obrázek v moha ruzných formátech (mimo jiné jako postscriptový soubor pro úcely publikace v knize ci časopise a png-soubor (případně gif) pro zveřejnění grafu na "webu"). Samozřejmě, stačí napsat help postscript případně help png či help gif a dozvíme se jak na to.
Jak asi začíná být zřejmé, program gnuplot nám v přednášce postačí pro běžné malování křivek a pro svoji jednoduchost a pružnost se vám nejspíš stane uzitečným pomocníkem i v následujících letech . Až budeme ovšem v přednášce hovořit o 2D grafice a budeme místo průbehu funkcí třeba vybarvovat trojúhelníky, použijeme jinou metodu.
Podle toho, že v Pascalu máme zdarma tak málo matematických funkcí (abs, sqr, sqrt, sin, cos, arctan, exp a ln) by jeden mohl hádat, že Wirth měl aversi k matemtické analýze. Pravděpodobne ale jde o důsledné uplatnění principu jednoduchosti. Protože prehršle různých funkcí znamenala nezbytně prodloužení manuálu a právě nepřehlednost jazyků té éry, byla tím, co informatici generace autora Pascalu velmi kritizovali. Osud jazyka PL/I napovídá, že nejspíš měli v něčem pravdu.
Znamená to snad, že se tedy např. máme navždy smírit s absencí funkce ArcSin v Pascalu? Protože víme, že mužeme definovat nové funkce, je odpoved jasná: definujeme funkci ArcSin:
function ArcSin(sinus : real) : real;
{ spocte uhel, jehoz sinus zname }
var cosinus: real;
begin
cosinus := sqrt(1-sqr(sinus)); {bereme vzdy znamenko +sqrt(...)}
if cosinus=0 then if sinus>0 then ArcSin := Pi/2
else ArcSin := -Pi/2
else ArcSin := ArcTan( sinus / cosinus );
end;
A je to! Za povšiknutí stojí, že výpočet se zhroutí pokud bychom chtěli počítat arcusinus arumentu v abolutní hodnotě větší než jedna.
Často jsou funkce dány ve formě mocninné řady. Vezměme třeba následující vzorec pro výpočet obvodu elipsy:
Tento vzoreček si říká o přímočarý přepis. Jedinou otázkou je jak dlouho řadu sčítat. Budeme předpokládat, že řada konverguje dostatečně rychle, takže ukončení rady členem nějaké velikosti znamená chybu ve výpoctu stejného rádu (viz dále). V okamžiku, kdy tento předpoklad neplatí, není řada vhodná pro sčítání a musíme nalézt jinou formulku [Jarník Integrání pocet II].
function ObvodElipsy(a,b : real) : real;
const posledni = 1E-12;
var epsilon,
s,ds,f2: real;
k : integer;
begin
epsilon := sqrt(a*a-b*b)/a;
s := 1;
k := 1;
f2 := 1; {sqr(1*3*5*.../(2*4*6*...))*eps^2k}
repeat
f2 := f2*sqr((k+k-1)/(k+k)*epsilon);
ds := f2/(k+k-1);
s := s-ds;
k := k+1;
until ds<posledni;
ObvodElipsy := 2*Pi*a*s;
end;
Všimněte si postupu obvyklého u takovéhoto typu sčítání řad. Obecně se snažíme provádět uvnitř cyklu co nejméně operací, a protože lze většinou jednoduše k-tý koeficient odvodit z toho předchozího, není potřeba do cyklu sčítání vkládat ještě cyklus počítající všechny ty součiny. (Puntičkář by možná ještě odstranil dělení v přirazení ds := f2/(k+k-1) ). Daleko důlezitejší neř pár zbytecných operací je ovšem vědět, v jakémrozsahu parametrů se na funkci můžeme spolehnout. To je ovšem především záležitost matematické analýzy. Pokud má funkce jednoduchou formu závislosti na parametrech lze ale chování "naprogramované" funkce ověřit. Pro představu je na ásledujícím obrázku závistlost relativní chyby výsledku volání funkce ObvodElipsy(1,x) na velikosti vedlejší poloosy. Pripomeňme si, že jsme zvolili const posledni = 1E-12; a vzhledem k přesnosti zvolené metody bychom asi měli nekam do kódu přidat varování, pokud podíl parametrů b/a není dostatecne velký.
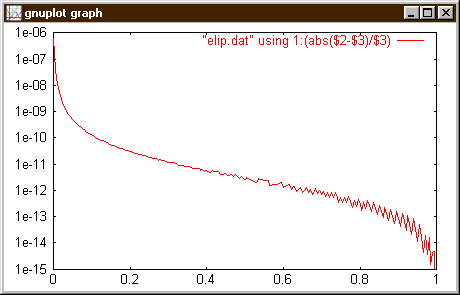
Námět na přemýšlení: jak získat data potřebná pro určení chyby metody, když nemáme po ruce přesné hodnoty s výjimkou b=a a b=0, tedy kruznice a úsecky?
Rekurentní vztahy
Nejjednodušším příkladem je samozřejmě funkce faktoriál:.
n! = n (n-1)!
0! = 1
Jiným standardním příkladem je Fibonacciho posloupnost:
F(n) = F(n-2)+F(n-1)
F(0) = 0
F(1) = 1
Jakkoli je nasnadě použít pro výpočet prostředky rekurse jazyka Pascal, nebudeme je v toěchto případech používat. Programová rekurse je znázorněna pro faktorial takto:
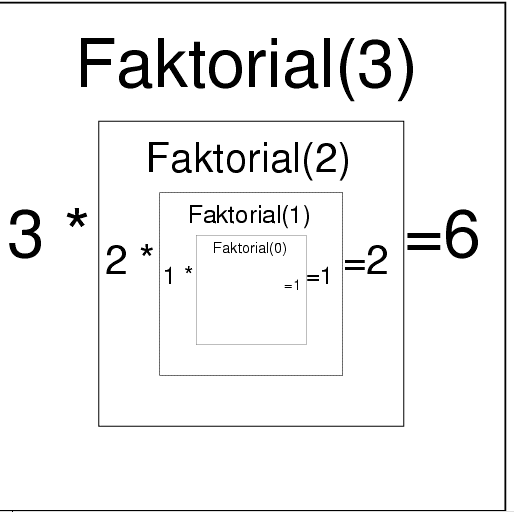
a odpovídá následujícímu kódu:
function faktorial(a:integer):real;
begin if a<=1 then faktorial := 1
else faktorial := a*faktorial(a-1);
end;
Pro Fibonacciho posloupnost takto
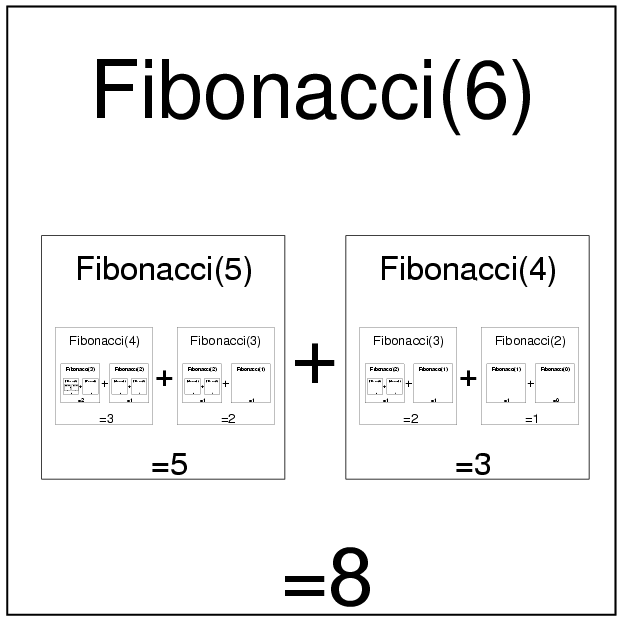
kde je nevhodnost programové rekurse naprosto zřejmá.
Cvicení: Vyzkoušejte si napsat rekurentní
versi funkce Fibonacci(n : integer).
Cvicení: Kolikrát se zavolá funkce Fibonacci,
kdyz se takto pokoušíme spočíst Fibonacci(6)?
Jak tedy převedeme matematický rekurentní vztah na návod pro počítač? Nejjednodušší je samozrejme případ funkce faktorial
function faktorial(a:integer):real;
var i : integer;
s : real
begin
s:=1;
for i:=2 to a do s := s*i;
faktorial := s;
end;
Takto zapsaný postup má jediný háček: vrací rozumnou
hodntu i pro záporné hodnoty parametru a. Podobně
jako by nebylo nejlepší, kdyby nám sqrt vracelo nulu
pro záporné parametry (dáváme přednost krachu programu),
měli bychom přidat test na záporné hodnoty a a
program případně ukončit.
Cvičení: Zkuste na cyklus prevést výpocet
funkce Fibonacci.
Zde si ukázeme, jak převést na cyklus složitější variantu Fibonacciho vztahu. Zadání, které nalezneme v učebnici fyziky zní:
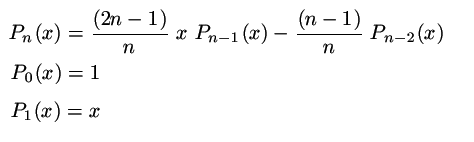
kde Pn(x) je tzv. Legendreuv polynom a během studia jej mnohokrát potkáte. Pro nás je úloha omezena na nalezení hodnoty Pn(x) pro dané celé n>=0 a reálné x. Jak je vidět, je potřeba rozlišit případy n=0, n=1 a zbytek, kdy použijeme uvedenou formulku opakovaně (n-1)-krát. Zde je jedna z variant:
function LegendreP( m : integer; x : real ) : real;
var Pn2, Pn1,Pn : real;
n : integer;
begin Pn := 1; {P0(x)}
if m = 1 then Pn := x; {P1(x)}
Pn2 := 1;
Pn1 := x;
for n := 2 to m do begin Pn := ((n+n-1)*x*Pn1 - (n-1)*Pn2 )/n; Pn2:= Pn1; {Pn->Pn1->Pn2} Pn1:= Pn; end;
LegendreP := Pn;
end;
Příkaz cyklu for se nám postará o zvyšování n od 2 až do m, ale s každým zvýšením hodnoty n je potřeba také posunout hodnoty v proměnných, které si "pamatují" hodnoty Pn-2 a Pn-1.
Pro vykreslení použijeme následující program
program MalujLegendreovyPolynomy;
const xa = -1;
xb = 1;
N = 400;
function LegendreP( m : integer; x : real ) : real;
...... viz výše ....
var k,i : integer;
x,y : real;
begin
for k := 0 to 12 do begin
for i := 0 to N do begin
x := xa + (xb-xa)*i/N;
writeln(x,' ',LegendreP(k,x));
end; {graf pro pevne x}
writeln; {vypiš dva prázdné rádky}
writeln;
end; {dalsi k}
end.
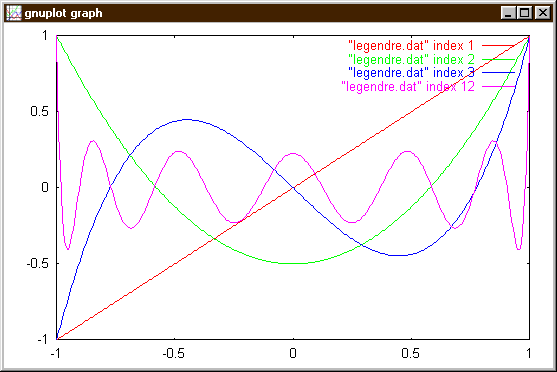
Ten vypíše tabulku hodnot Funkce P0(x), poté dva prázdné řádky, pak tabulku hodnot funkce P1(x), pak dva prázdné řádky atd. až nakonec tabulku funkčních hodnot P12(x). Zadáme-li programu guplot příkaz plot "legendre.dat", kde soubor legndre.dat obsahuje výstup našeho programu, dostaneme následující obrázek
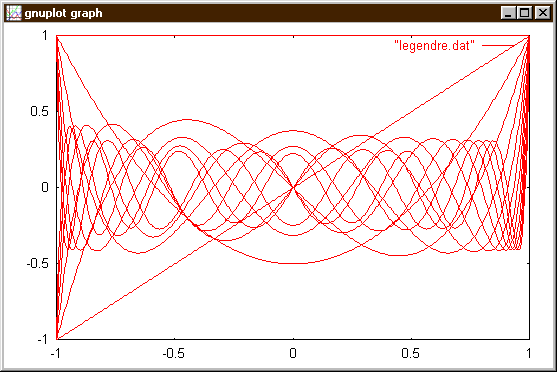
Protože jsme ale oddělili jednotlivé tabulky hodnot dvěma prázdnými řádky, můžeme si z toho zmatku vybrat jen ty křivky, které nás zajímají a to pomocí slova index následujícího za názvem datového souboru. Např.
plot "legendre.dat" index 1,"legendre.dat" index 2,"legendre.dat" index 3, "legendre.dat" index 12
nám vymaluje tabulky hodnot polynomu P1, P2, P3 a P12. Ještě se k tomu vrátíme v povídání o polích, ale je dobré vědet, že první sekci dat odpovídá index 0 a tak shodou okolností se index sekce shoduje s řádem Legendreova polynomu.
Pozor: někdy se může stát, že rekurentní vztah podobný výše uvedenému pro Legendrovy polynomy nefunguje, neboť s rostoucím n může do závratných výšek narůst úplně drobná počátecní nepřesnost. Diskuse tohoto jevu je ovšem mimo možnosti této prednášky.
Protože nás matematici učí, že spojité funkce můžeme aproximovat polynomy, často mají počítané funkce tvar polynomů. Následující funkce počítá s relativní chybou pod 1E-12 obvod elipsy. Hodnoty koeficientů polynomu samozřejmě spadly s nebe (od pana Čebyševa).
function ObvodElipsyP(a,b : real):real;
var x : real;
begin
x := sqrt(a*a-b*b)/a; {epsilon}
if x>0.5 then
begin
Writeln('Pouzivam aproximaci platnou do vystrednosti 0.5! ale chce se po me:',x);
Halt;
end;
x := (((((((((((-0.7447687857522e-1*x+0.1590001893248)*x-0.1740344498264)*x+0.1042163635809)
*x-0.5263574825627e-1)*x+0.1129877259030e-1)*x-0.2157908636362e-1)*x+0.2458101342560e-3)
*x-0.4689377871622e-1)*x+0.8483390673316e-6)*x-0.2500000198143)*x+0.1811318676024e-9)*x+0.9999999999997;
ObvodElipsyP := 2*Pi*a*x;
end;
Za povšimnutí stojí jen způsob, jímž je polynom vyčíslován. Vidíme, že se nikde nemusí počítat bůhvíjaké mocniny x, vše vyřešil Mgr. Horner pomocí závorek a celé se to po něm jmenuje Hornerovo schéma.
Tvoří velmi důležitou třídu algoritmů. Povětšinou spočívají v aplikaci zázračné formulky, která říká jak z méně přesného výsledku vyrobit výsledek přesnější a jejím opakování až do dosažení požadované přesnosti. Zde si ukážeme jak několik takových formulek a algoritmů na nich založených.
Půlení intervalu
Nabývá-li spojitá funkce v bodě a zápornou a v bodě b kladnou hodnotu, musí se nejméně jeden kořen funkce nacházet někde mezi těmito dvěma hodnotami. Zkusíme-li uprostřed spočíst funkční hodnotu uprostřed intervalu v bodě c=(a+b)/2 buď rovnou nalezneme kořen, nebo nalezneme kratší podinterval, ve kterém se kořen zaručeně nachází. Podle znaménka c je to buď <a,c> nebo <c,b>. Pokud je tento podinterval ještě stále moc velký, celý postup opakujeme. Délky intervalů tvoří geometrickou posloupnost s kvocientem 1/2. Proto každých deset iterací přidá tři desetinná místa a po 52 iteracích dosáhneme přesnosti s níž je uložena neznámá, pokud uvažujeme, že jsme začali s intervalem <1,2>. Pokud bychom se na reálnou proměnnou dívali ve dvojkovém zápise, dá se zhruba říci, že v každém kroku iterace přidáme jeden bit přesnosti. Toto je nejpomalejší metoda hledání kořene ale musíme ji ovládat. Pokud totiž máme dost času a nebo je funkce do té míry ošklivá, že rychlejší metody nemůžeme použít, je rozumné použít půlení ntervalu pro jeho spolehlivost.
Newtonova metoda
Na rozdíl od půlení intervalu, vyžaduje newtonova metoda, aby poblíž kořene byla funkce dostatečne hladká. To proto, že metoda předpokládá, že funkci lze nahradit prvním diferenciálem a ten jako lineární rovnici použít k hledání kořene:
f(x1) = f(xo+dx) = f(xo) + f'(xo) dx = 0
a tedy
x1 = xo+dx = xo - f(xo)/f'(xo)
Jako příklad použijeme snad nejjednodušší možný
problém - výpočet převrácené hodnoty čísla. Představme
si na chvíli, že Pascal spolu s umocňováním neovládá ani
dělení. Co teď? Podíl a/b můžeme vyjádřit jako
součin a s převrácenou hodnotou b. Jak ale
spočíst převrácenou hodnotu? Zkusíme hledat kořen rovnice
f(x) = b-1/x
Newtonova motetoda říká,. že pokud vezmeme xo dostatečne blízko kořene bude číslo
x1 = xo+dx = xo - f(xo)/f'(xo) = x + x(1-bx)
ještě mnohem blíže. Vidíme, že na vypočtení nám stačí pouze násobení a sčítání. Že by bylo možné převést dělení na sérii násobení a sčítání?
Nejdříve to zkusíme pro konkrétní hodnotu např. 0.9 a první přiblížení převrácené hodnoty odhadneme na 1.1. K jaké posloupnosti přiblížení převrácené hodnoty 1/0.9 povede Newtonova metoda?
xo =1
x1 =1.1
x2 =1.111
x3 =1.1111111
x4 =1.111111111111111
Vidíme, že zatímco půlení intervalu by přidalo 0.3 cifry na iteraci, dosáhli jsme v každém kroku zdvojnásobení počtu platných cifer a potřech iteracích musíme skončit, protože již neumíme čísla ukládat přesněji. Chování chyby se dá studovat obeně, my ale pro jednoduchost použijeme konkrétní funkci odpovídající výpočtu převrácené hodnoty.
Metoda regula falsi
Ne vždy ale dokážeme spočítat hodnotu derivace. Jistým vylepšením metody půlení intervalu je předpokládat, že funkce mezi body a a b vypadá téměř jako úsečka a zkoušet místo půlky intervalu vzít jako kandidáta na kořen prusečík této sečny s osou x, tedy
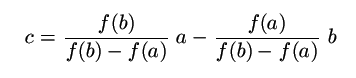
Nyní se podobně jako u půlení intervalu rozhodneme podle znaménka f(c) tak aby kořen ležel ve zvoleném intervalu. Pro funkce, které nemění v blízkosti kořene znaménko druhé derivace tato metoda neustále upravuje jen jednu mez, jak uvidíme v našem příkladu s dělením:
[a0,b0] = [1,
1.200000000000000]
[a1,b1] = [1,
1.120000000000000]
[a2,b2] = [1,
1.112000000000000]
[a3,b3] = [1,
1.111200000000000]
[a4,b4] = [1,
1.111120000000000]
[a5,b5] = [1,
1.111112000000000]
[a6,b6] = [1,
1.111111200000000]
[a7,b7] = [1,
1.111111120000000]
[a8,b8] = [1,
1.111111112000000]
[a9,b9] = [1,
1.111111111200000]
[a10,b10] = [1,
1.111111111120000]
[a11,b11] = [1,
1.111111111112000]
[a12,b12] = [1,
1.111111111111200]
[a13,b13] = [1,
1.111111111111120]
[a14,b14] = [1,
1.111111111111112]
[a15,b15] = [1,
1.111111111111111]
Zjednodušeně se dá říci, že v každé iteraci přibude tolik cifer, na kolik se trafíme na začátku. Jakkoli nemůže tato metoda kořen "ztratit", může se stát, že se metoda regual falsi chová i hůře než půlení intervalu.
Metoda sečen
To že jeden z krajních bodů zůstával v minulé metodě trčet na místě, výrazně snižovalo rychlost konvergence. Pokud upstíme od požadavku různých znamének funkce f v bodech a a b, můžeme mít vždy po ruce poslední a předposlední aproximaci kořene a z nih počítat odhad polohy kořene podle stejného vzorce. Ten navíc upravíme na následující tvar:
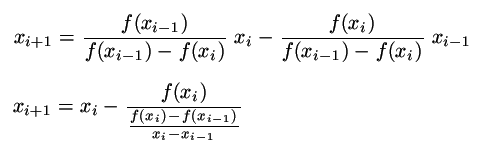
Všimněte si, že jmenovatel ve složeném zlomku je aproximací derivace funkce. Protože se nyní obě hodnoty přibližují kořeni, nepřekvapí, že účinnost metody se blíží Newtově metodě.
[a0,b0] =
[1.000000000000000,
1.200000000000000]
[a1,b1] =
[1.200000000000000,
1.120000000000000]
[a2,b2] =
[1.120000000000000, 1.110400000000000]
[a3,b3] =
[1.110400000000000, 1.111116800000000]
[a4,b4] =
[1.111116800000000, 1.111111114751999]
[a5,b5] =
[1.111111114751999, 1.111111111111092]
[a6,b6] =
[1.111111111111092, 1.111111111111111]
Cvičení: Napište programy, které vypíší postup hledání kořene, a zkotrolují, zda jsem si ta výše uvedená data nevycucal z prstu.
Mnoľiny
Z výąe uvedených typů můľeme budovat typ mnoľina:
program test;
type tCharSet = set of char;
var PouzitaPismena,RozbiteKlavesy : tCharSet;
c : char;
begin
RozbiteKlavesy := ['x','q','X','Q'];
PouzitaPismena := []; //prázdná mnoľina
repeat
read(c);
PouzitaPismena := PouzitaPismena+[c];
until c='.';
if PouzitaPismena*RozbiteKlavesy = [] then Writeln('Mohu Pouzit Tento Psaci Stroj')
else Writeln('Musim Pouzit Jiny Psaci Stroj');
readln;
readln;
end.
Konstruktor mnoľiny: má podobu hodnot a intervalů
oddělených čárkami v hranatých závorkách.
K disposici jsou obvyklé mnoľinové operace:
Sjednocení +, průnik *, rozdíl -. Logické operace nad mnoľinami jsou jen podmnoľina <=, nadmnoľina >= , rovnost = a různost <>. Klíčové slovo in lze pouľít ke konstrukci dotazu na přítomnost prvku v mnoľině, takľe
LogProm := Znak in Mnozina;
je totéľ jako
LogProm := [Znak] <= Mnozina;
Dálnopisným ekvivalentem znaku [ kombinace (. a podoně .)
nahradí znak ] .
Z výąe definovaného typu tKarty můľeme sestavit mnoľiny
const sSedmy = [ZelenaSedma..SrdcovaSedma];
sOsmy = [ZelenaOsma..SrdcovaOsma];
{...}
sEsa = [ZeleneEso..SrdcoveEso];
a testovat hodnotu karty vyrazem (k in sSedmy) misto (k<=SrdcovaSedma)
and (k>=ZelenaSedma).
Neplánované chyby při běhu programu
Následujíc program nám vypíąe jako výsledek číslo 0. Je to pochopitelný, ale nejspíą nechtěný jev. Chyba spočívá v tom, ľe číslo 256 nepatří do rozsahu typu byte, který je 0..255.
program test; var i : byte; begin i:=255; i:=i+1; writeln(i); readln; end.
Proto program trochu ozdobíme:
program test;
uses SysUtils;
var i : byte;
{$RANGECHECKS ON} {kamkoli nad radek i:=i+1}
begin
i:=255;
i:=i+1;
writeln(i);
readln;
end.
Vloľením
{$RANGECHECKS ON} komentáře začínajícího
zankem dolaru jsme překladač uplatili, aby do přeloľeného
kódu přidal kontrolu na meze při přiřazování a
indexování polí. Pozor tedy na znak $ nacházející se za
sloľenou závorkou nebo jejím dálnopisným ekvivalentem (*,
trerý také můľe omezovat komentář. Po přidání {$RANGECHECKS ON} se vypsání
nuly nedočkáme, místo toho se pos tsiknutí F9 (zkratka pro
spuątění programu) objeví varování:
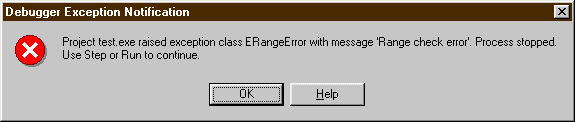
a my po odklepnutí OK musíme v menu vývojového prosředí Delphi zvolit Run/Program Reset abychom se zbavili toho modrého zvýrazněného řádku s chybou.
Pokud místo práce ve vývojovém prostředí nastane chyba
při běhu aplikace spuątěné z příkazové řádky, jsme
upozorněni známým varováním, ľe program selhal:
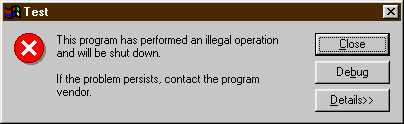
Pokud by mezi importovanými kniovnami nebyla knihovna SysUtils, skončil by program jen vypsáním chybové hláąky, coľ nám větąinou nestačí pro nalezení a odstranění chyby:
C:\Projects\prog\pokusy>test Runtime error 201 at 00402570 C:\Projects\prog\pokusy> |
Podobně jako se výsledek nemusí vejít do proměnné, můľe se také stát, ľe se výsledek aritmetické oprace, řekněme násobení, vůbec nevejde do překladačem předpokládané délky slova 32 bitů, a operace vrací nesmysly. V tomto případě jde o jiný typ chyby, tzv přetečení a odpovídá jí jiný přepínač: {$OVERFLOWCHECKS ON}, v krátkém (turbopascalovém) znění {$Q+}.
program test;
uses sysutils;
var j : integer;
{$OVERFLOWCHECKS ON}
begin
j:=50000;
j:=j*j;
writeln(j);
readln;
end.
Pouľíváme knihovny ( Velmi úvodní poznámky)
Uvedení ľádosti o pouľití knihoven, např.
Uses SysUtils;
musí následovat před oddílem deklarací a má formu rezervovaného slova uses následovaného seznamem identifikátorů oddělených čárkami a ukončeného, ovąem, středníkem.
Import knihovny pomocí
konstrukce
uses
IdKnihovny1,IdKnihovny2,...,IdKnihovnyN;
si můľeme představit jako
zkratku za napsání deklarací vąeho co uvedené knihovny exportují.
Přečteme-li si v nápovědě:
Unit SysUtils function IsLeapYear(Year: Word): Boolean;
Description
Call IsLeapYear to determine whether the year specified by
the Year parameter is a leap year. Year specifies the calendar
year.
znamená to, ľe v knihovnou SysUtils je kromě jiného
poskytována fukce, která pro letopočty z rozsahu 0..65535
vrátí logickou hodnotu určující, zda jde o rok přestupný,
či nikoli. Pouľijeme-li tedy spojení
uses SysUtils;
můľeme funkci IsLeapYear pouľívat, jako bychom si její deklaraci do programu
napsali sami.
Jak jsme viděli na chování běhových chyb, pouľití knihovny můľe mít své důsledky, aniľ vůbec pouľijeme jakoukoli funkci či proceduru z knihovny. Bohuľel vąak podrobnějąí popis přesahuje rámec přednáąky.
Z desítek knihove stndardně dodávaných s Delphi 6, bude pro nás asi zajímavějąí knihovna Math, sdruľující
mnoho uľitečných matematických funkcí opatřených
rozumnými identifikátory. Jsou mezi nimi např. goniometrické
funkce (ArcCos), umocňování (Power), převodní funkce
(DegToRad) atp.
Pokud si pamatujeme alespoň počáteční
písmena identifikátoru, můľeme vyuľít pomoci, kterou nám
nabízí pracovní prostředí:
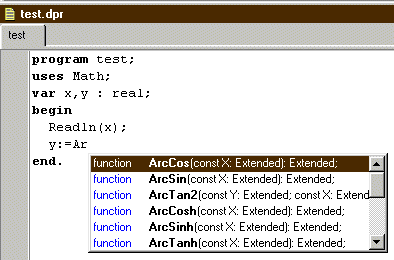
Pokud po napsání několika písmen pouľijeme klávesovou zkratku Ctrl-Mezera, objeví se nám výběr identifikátorů začínajících na daná písmena. Po napsání kompletního identifikátoru a otvírací závorky nám navíc editor nabídne nápovědu v podobě seznamu formálních parametrů a jejich typů:

V knihovně Math je definováno nepřehledné mnoľství
goniometrických a příbuzných funkcí
ArcCos,ArcCosh,ArcCot,ArcCotH,ArcCsc,ArcCscH,ArcSec,ArcSecH,ArcSin,ArcSinh
ArcTan2,ArcTanh,Cosh,Cosecant,Cotan,CotH,Csc,CscH,Sec,Secant,SecH,Sinh,Tan,Tanh
a dále např.
Sign(x) ... vrací -1,0,+1 tak aby x
= Sign(x)*Abs(x)
Ceil(x) ... nejmenąí celé vetąí
Floor(x) ... nejvetąí celé menąí
nebo logaritmy
Log10(x)
Log2(x)
LogN(10,x)
funkce pro umocňování
Power(10,x)
IntPower(3,k)
zaokrouhlování
RoundTo(x,-2) ... na dvě desetinná
místa
porovnávání reálných čísel s tolerancí
if SameValue(x,y,1E-10) then ...
if CompareValue(x,y,1E-12)<=0 then ....
Rozhodně tu nemůľeme očekávat Besselovy funkce a pod.
I data mají svou strukturu
Kromě deklarací proměnných, konstant, procedur a funkcí můľeme v jazyce Pascal deklarovat i nový typ. Prozatím jsme pouľívaly několik jednoduchých typů:
Integer (a příbuzné varianty byte, ..., int64)
Real (i ten má kratąí variantu: single)
Boolean
Char
Daląím jednoduchým typem je char.
Konstanta tohoto typu se zapisuje jako
1. jeden znak mezi apostrofy, např. ' ' (mezera) nebo '*' nebo '''', coľ je jediný znak apostrof.
2. znak # následovaný číslem v rozsahu 0..255. Toto číslo
můľe být téľ psáno pomocí znaku $ v hexadecimálním
zápisu, např. #9 (znak tabulátor), #32 (mezera) je totéľ
jako #$20 nebo samozřejmě ' '. Souvislost mezi číselným
zápisem a přísluąným znakem je dána tabulou kódů, která
se z historických důvodů jmenuje ASCII
(americký standardní kód pro výměnu informací).
#$20=#32= ' ' '!' '"' '#' '$' '%' '&' '''' '(' ')' '*' '+' ',' '-' '.' '/'
#$30=#48= '0' '1' '2' '3' '4' '5' '6' '7' '8' '9' ':' ';' '<' '=' '>' '?'
#$40=#64= '@' 'A' 'B' 'C' 'D' 'E' 'F' 'G' 'H' 'I' 'J' 'K' 'L' 'M' 'N' 'O'
#$50=#80= 'P' 'Q' 'R' 'S' 'T' 'U' 'V' 'W' 'X' 'Y' 'Z' '[' '\' ']' '^' '_'
#$60=#96= '`' 'a' 'b' 'c' 'd' 'e' 'f' 'g' 'h' 'i' 'j' 'k' 'l' 'm' 'n' 'o'
#$70=#112='p' 'q' 'r' 's' 't' 'u' 'v' 'w' 'x' 'y' 'z' '{' '|' '}' '~' #127
Znaky #0..#31 nemají původně význam znaků ale kontrolích
povelů (původně pro dálnopis).
Znak #9 se nazývá tabulátor, znaky #10 a #13 mají význam
přechodu na nový řádek, případně jen "návratu
vozíku".
Ostatní znaky z tohoto rozsahu mohou mít podle situace význam
řídícího znaku nebo jen třeba jen znaku srdíčka. Pokud k
tomu nemáme dobrý důvod (např. níľe zvědavost)
neposíláme do textového výstupu kontrolní znaky a pro
řádkování pouľíváme Writeln. Ten vypíąe na kaľdé
platformě platnou sekvenci kontrolních zanků pro přechod na
nový řádek. S tabulátorem nebývají potíľe.
Proměnná typu char se deklaruje podle očekávání jako
var c : char;
Pro ujasnění významu znaků mezi 9 a 13 vyzkouąejte co vypíąe
writeln('abcd',#13,'12');
Případně jednoduchý cyklus
var c:char;
...
for c:=#9 to #13 do
begin
writeln(ord(c),':');
writeln('abcd',c,'12');
end;
Jak vidíme, proměnná typu char můľe vystupovat jako
řídící proměnná cyklu for.
Pořadí znaku v tabulce (tedy číslo, kterým počítač znak
representuje) získáme pouľitím funkce ord.
Naopak znak z celého čísla vyrobíme pouľitím konverse typu tak,
ľe idnetifikátor typu pouľijeme jako funci s jedním
parametrem. Proto následující kód dá stejný výstup.
var i:integer;
...
for i:=9 to 13 do
begin
writeln(i,':');
writeln('abcd',char(i),'12');
end;
Proto také můľeme místo ord(c) psát integer(c).
Spolu s celočíselnými typy je typ char příkladem tzv ordinálního typu, tedy typu repsesentujícího mnoľinu s bobře definovaným uspořádáním, 1:1 zobrazitelnou na nějaký (konečný-víc se nám do počítače nevejde) interval celých čísel. Pro takovou mnoľinu je pak rozumné definovat funkce předchůdce (pred) a následník (succ).
pred('B') = 'A', pred(0) = -1, succ(7) = 8 atp.
Deklarace typu
Následující řádek deklaruje typ int a to jako integer.
type int = integer;
tím získáme moľost uąetřit si trochu psaní. Můľeme ale také napsat
type integer = int64
a naučit náą program počítat místo do 2 147 483 647 aľ do 9 223 372 036 854 775 807. Tím ľe takto počínaje touto deklarací zastíníme původní význam identifikátoru si ovąem můľeme přidělat řadu starostí, takľe jde o trik nevhodný pro seriózní práci.
Je zřejmé, ľe takto bychom se daleko nedostali, pouze bychom mohli nazývat star=é věci novým jménem. Pascal přináąí řadu daląích způsobů, jak zkonstruovat nový typ.
Typ Interval
Nejjednoduąąí moľností je prohlásit, ľe proměnná smí nabývat pouze hodnot z jistého intervalu ordinálního typu:
type tCisloPoslance = 1..200;
tMalePismeno = 'a'..'z';
tRocnikZS = 1..9;
var PredsedaPK : tCisloPoslance;
Vychodil : tRocnikZS;
Takto máme moľnost přenechat komilátoru starost o to, aby nám nehlasovalo přílią mnoho poslanců nebo zda vyplnili správně svoji povinnou ąkolní docházku. Prostřednictvím chybových hláąení při kompilaci či běhu se tak můľeme dozvědět o nesrovnalostech.
Uvidíme později, ľe daleko nejdůleľitějąím uľitím typu interval je určení mezí polí, které chápe Pascal jako zobrazení z intervalu do mnoľiny dané typem prvku pole.
Výčtový typ
Je jakýmsi zobecněním typu interval, kde si můľeme prvky sami pojemnovat a nejde jen o podmnoľinu výchozího typu.
type Fukce = (Radovy, ClenVyboru, PredsedaKlubu);
deklaruje nejen nový typ ale téľ nové hodnoty v podobě
identifikátorů. Kormě funkce ord, která nám dává
ord(Radovy) = 0, atd... máme opět k disposici také succ a
pred, takze plati
succ(Radovy) = pred(PredsedaKlubu)
Pro počítač je tahle deklarace podobná svým významem
následující
const Radovy = 0;
ClenVyboru = 1;
PredsedaKlubu = 2;
type Funkce = Radovy..PresedaKlubu;
ovąem jde o izolovaný ty a nemůľeme do proměnné výčtového typu přiřadit celé číslo. To zvyąuje bepečí při psaní programu.
Pozor identifikátory prvků výčtového typu nám moho něco zastínit, nebo vést ke kolizi, takľe i zde musíme dávat pozor při volbě jmen. Situace je velmi podobná té při deklaraci const ClenVyboru = 1;
Někdy má smysl "Maďarská notace":
type tFukce = (eRadovy, eClenVyboru, ePredsedaKlubu);
Zde je jiný příklad:
type tKarty = (
ZelenaSedma, ZaludovaSedma, KulovaSedma, SrdcovaSedma,
ZelenaOsma, ZaludovaOsma, KulovaOsma, SrdcovaOsma,
ZelenaDevitka, ZaludovaDevitka, KulovaDevitka, SrdcovaDevitka,
ZelenaDesitka, ZaludovaDesitka, KulovaDesitka, SrdcovaDesitka,
ZelenySpodek, ZaludovySpodek, KulovySpodek, SrdcovySpodek,
ZelenySvrsek, ZaludovySvrsek, KulovySvrsek, SrdcovySvrsek,
ZelenyKral, ZaludovyKral, KulovyKral, SrdcovyKral,
ZeleneEso, ZaludoveEso, KuloveEso, SrdcoveEso
);
type tSedmy = ZelenaSedma..SrdcovaSedma;
tOsmy = ZelenaOsma..SrdcovaOsma;
{...}
var SedmaKDalsimuPouziti : tSedmy;
LibovolnaKarta : tKarty;
begin LibovolnaKarta := ZaludovyKral; SedmaKDalsimuPouziti := SrdcovaOsma; //[Error] pokus.dpr(28): Constant expression violates subrange bounds ... LibovolnaKarta := ZaludovyKral; SedmaKDalsimuPouziti := LibovolnaKarta; writeln( ord(SedmaKDalsimuPouziti)); // Writeln neumi vypsat vyraz vyctoveho typu readln; end.
Strukturované typy II - Pole
(anglicky array) je jiľ od počátku počítačového věku nejdůleľitějąí datovou strukturou.
Píąeme
const Dim = 3;
type tVektor3 = array[1..Dim] of real;
var a : tVektor3;
x : real;
i : integer;
b : tVektor3;
a myslíme tím, ľe proměnná a je skupina tří reálných čísel. Při deklaraci strukturovaného typu pole musíme uvést typ prvku pole a typ indexu. Typ indexu musí být ordinální typ s dostatečně malým rozsahem hodnot. Větąinou píąeme místo typu indexu rovnou interval, ale nikdo nám nebrání psát
type t3Dindex = 1..Dim;
tVektor3 = array[t3Dindex] of real;
Operace s Poli: Přístup k prvku pole
S jednotlivými prvky pole můľeme pracovat zvláą» tak, ľe
za identifikátor proměnné typu pole přidáme v hranatých
závorkách index:
a[1] := 0; a[2] := x+1; a[3] := x-1;
Identifikátor pole následovaný výrazem v závorkách je první příklad toho, kdy designator není pouhý identifikátor. Vzpomeneme-li si na synatktické diagramy z druhé přednáąky, uvidíme, ľe přístup k prvku pole můľeme pouľít na levé straně přiřazovacího příkazu stejně jako ve výraze, pokud tam můľeme pouľít proměnnou typu z něhoľ je pole utvořeno.
x := a[1]+a[2]+a[3];
je tedy správně zapsaný přiřazovací příkaz. Kdybychom jako indexy pouľívali pouze konstanty, vystačili bychom se třemi proměnnými a1, a2, a3. Důleľité je, ľe jako index můľeme pouľít libovolný výraz kompatibilní s typem indexu udaným při deklaraci. Výąe uvedený součet tedy můľeme zapsat cyklem.
x := 0; for i := 1 to Dim do x := x + a[i];
Podobně jako v přiřazovacím příkazu můľe me pouľít prvek pole jako parametr.
for i := 1 to Dim do Writeln(i, ' ' , a[i]);
Vzhledem k deklaraci spadá ve vąech krocích i do intervalu 1..Dim a nedojde tedy běhové chybě. Jiľ víme, ľe při deklaraci pole musíme uvést typ prvku pole a typ indexu. Při přístupu k prvku pole, a» jiľ na některé ze stran přiřazovacího příkazu, nebo jako parametru volání procedury či funkce, teď kromě samozřejmé podmínky na typ prvku pole (ani nyní nemůľeme psát CelePole[i]:=RealnePole[i] ), musíme navíc dbát o to aby index byl v povolených mezích.
Operace s Poli: Přiřazení
Pokud vytvoříme nový typ, neumí Pascal s proměnnými tohoto
typu přílią zacházet. Kromě setupu na niľąí úroveň,
coľ pro strukturovaný typ pole je pouľití konstrukce Ident[index],
umí jazyk Pascal přiřazovat mezi dvěma proměnnými stejného
typu. Dva typy s odliąnými identifikátory jsou stejné pokud
jsou navzájem svázány řadou rovnítek v deklaraci typů, kde
na obou stranách rovnítka je jen a pouze identifikátor.
type Typ1 = array [1..6] of integer; Typ2 = array [1..6] of integer; Typ3 = Typ1; Typ4 = Typ1; // Typ3 je stjený s Typ2 var Z1,Y1: Typ1; Z2,Y2: Typ2; Z3 : Typ3; Z4 : Typ4;
... Z1 := Y1; // OK Z3 := Z1; // OK Z2 := Y2; // OK Z3 := Z4; // OK ... Z1 := Z2; // NE! Z2 := Z3; // NE!
Chceme-li roząířit schopnosti jazyka pracovat s nově definovaným typem, musíme pouľít procedury a funkce, které mají některý z parametrů tohoto typu.
Operace s Poli: Procedury a funkce
Z předchozího vyplývá, ľe naąe vektory nemůľeme sčítat,
jak bychom chtěli:
type tVektor3 = array[1..3] of real;
var a,b,c : tVektor3;
x : real;
...
a := b+c; // NE!!!!
Bohuľel, Pascal nám ( aľ na výjmimy jako je překladač FreePascal ) neumoľňuje dodat definici operace '+' pro pole. Proto musíme psát:
procedure SectiV3( a,b : tVektor3; var c : tVektor3); begin c[1] := a[1]+b[1]; c[2] := a[2]+b[2]; c[3] := a[3]+b[3]; end; ... SectiV3(b,c, a);
nebo
function SectiV3( a,b : tVektor3) : tVektor3; begin SectiV3[1] := a[1]+b[1]; SectiV3[2] := a[2]+b[2]; SectiV3[3] := a[3]+b[3]; end; ... a := SectiV3(b,c);
Tato druhá varianta vypadá přehledněji, ale jde spíąe o výjimečné pouľití funkce vracející hodnotu strukturovaného typu. Jde o konstrukci, kterou připouątějí aľ současné překladače Pascalu. Měli bychom mít na paměti, ľe v tomto případě probíhá stěhování výsledku nadvakrát, nicméně, moľnost zapsat formulky aspoň trochu čitelně je příjemná:
a := SectiV3(VektorovySoucin(b,c),VektorovySoucin(d,a));
Kdy předávat pole odkazem?
Aľ na výjimky pokaľdé! Proto náą příklad
a := SectiV3(b,c);
s vektorovou algebrou byl ąpatně hned dvakrát. nejen, ľe zbytečně kopíroval jeden výsledek funkce do cílové proměnné při přiřazení, ale předevąím dvakrát kopíroval hodnotu obou parametrů předávaných hodnotou. Proto pro seriózní práci s poli budeme muset vąechna předání pole uskutečnit odkazem. Tím přijdeme o moľnost psát Součetpoli(VektorovysSoucin(a,b),c). Protoľe pole mohou být opravdu velká a mohou zabírat velké mnoľství paměti, můľe být daląím důvodem i neúnosná spotřeba paměti. Obecně musíme dbát o to aby reľie při volání procedury a navracení výsledku nebyla přílią velká (kolik je únosné? 5 nebo 50% ?).
Konstantní parametry
Přesto existuje moľnost, jak nekopírovat hodnoty hodnotou předávaných parametrů, kromě předání parametrů odkazem a hodnotou máme totiľ (v posledních letech) k dispozici tzv. konstantní parametry.
function SectiV3(const a,b : tVektor3) : tVektor3; begin SectiV3[1] := a[1]+b[1]; SectiV3[2] := a[2]+b[2]; SectiV3[3] := a[3]+b[3]; end;
Tím překladači sdělíme, ľe hodnotu parametru nehodláme
měnit, a on s ním bude zacházet ąikovněji, předevąím si
nebude vytvářet kopii. Jak víme, hlavička procedury nebo
funkce obsahuje nejn informaci pro kompilátor, ale vyjadřuje i
záměry autora. Identifkátor funkce by měl říkat co vrací.
Identifkátor procedury, co dělá, a idnetifikátory parametrů
by měly být také výmluvné. Pokud je naąím záměrem, aby
konkrétní parametr slouľil pro vstup hodnoty, je vhodné jej
označit jako konstantní. Tím se vyvarujeme moľné vchyby, kdy
se prostřednictvím parametru předávaného hodnotou pokusíme
něco vrátit. Kompilátor si bude stěľovat. Vyzkouąejte!
Pole s více indexy
Z typu tVektor3 bychom mohli deklarací
type tMatice3 = array [1..Dim] of tVektor3;
vyrobit typ tMatice3. Poté bychom mohli psát
var M: tMatice3;
b: tVektor3;
....
M[1][1]:=1; M[1,2]:=0; M[1,3]:=0; ....
b := M[1];
Naproti tomu deklarace
type tMatice3 = array [1..3] of array [1..3] of real;
nebo její zkrácená podoba
type tMatice3 = array [1..3,1..3] of real;
by nám nedovolila přiřazovat vektory do M[1] atd.
Příklady pouľití polí
Pole mají pro nás nepřeberné mnoľství uľití. Pro představu pár příkladů:
Seznam (index je jen pořadím v seznamu a nemá sám o sobě význam)
var TazenaCisla : array [1..6] of 1..49;
Časové řady (index je stále pořadím, ale má význam, lze z něj spočíst kdy doąlo k odečtní hodnoty)
var Teplota : array [1..PocetVzorku] of real;
2D data
var Teplota : array [1..PocetVzorkuX,1..PocetVzorkuY] of real;
2D obrázek (zatím stupně ąedi)
type tPixMap = array [1..PocetPixluX,1..PocetPixluY] of byte; var PixMap : tPixMap;
3D data
var Teplota : array [1..PocetVzorkuX,1..PocetVzorkuY,1..PocetVzorkuZ] of real;
Tabulka funkčních hodnot
var Faktorial : array [0..170] of real; // 171! se do proměnné typu real nevejde
Binomial : array [0..1000,0..1000] of real; //zkuste urcit presnejsi meze !!!
Tabulka na překódovani
var TajnyKod : array[char] of char;
ObrazkyKaret: array[tKarta] of tPixMap;
s1 : array[integer] of char; //[Error] pokus.dpr(25): Data type too large: exceeds 2 GB
s2 : array[real] of char; //[Error] pokus.dpr(26): Ordinal type required
Poslední dva řádky nejsou správně a je u nich uvedena chyba, kterou nám překladač ohlásí.
Pamě»ové nároky polí
Pole mohou velmi snadno vyčerpat dostupnou pamě». U polí s jedním indexem to jeątě není přílią aktuální. Pokud budeme ale psát program por odąumování audionahrávek a celou nahrávku se pokusíme nacpat do paměti najednou, můľeme narazit i tady. Pro představu si připomeňme známý fakt, ľe hodina stereofonní nahrávky v CD kvalitě nám zabere přes půl gigabytu (vzorek tvoří 2x16 bitů, rychlost vzorkování je 44 100 za sekundu). Daleko snaząí je vyčerpat pamě» při práci s poli se dvěma indexy. Takový RGB obrázek v rozliąení 10 000x10 000 zabere 300MB. Reálná matice se stejnými rozměry zabere skoro gigabyte. Jestliľe se nám můľe číslo 10 000 velké a můľeme doufat, ľe tak velké matice potřebovat nebudeme, ve třech dimenzích se situace jeątě zhorąí. Budeme-li chtít nějakou fyzikání veličinu definovanou v prostoru studovat na počítači, často nám nezbyde, neľ si prostor redukovat na prostorovou mříľ a pracovat s hodotami v uzlech této mříľe.
program KrychloHydro; const N = 200; type tGridFunction = array [1..N,1..N,1..N] var p,vx,vy,vz : tGridFunction;
....
Výąe uvedený začátek programu pro naivní počítačovou hydrodynamiku na krychli předpokládá, ľe na krychli o hraně dvěstě bodů budeme definovat tři komponety rychlosti a tlak. Těmito několika řádky jsme si vyľádali 256 MB paměti. Podle povahy problému se ukáľe, jestli nám 200 bodů stačí. Pokud budme potřebovat více, nesmíme zapomenout, ľe spotřeba paměti roste se třetí mocninou N.
Neľ budete psát diplomovou práci, pravděpodobně vzroste typická kapacita pamětí osobních počítačů 10x. To ovąem znamená, ľe dovolené N vzroste pouze dvakrát.
Eratosthenovo síto
je daląí klasický algoritmus, a navíc ilustruje, ľe pole potřebovali jiľ antičtí informatici.
program Sito;
const N = 50000000;
var MaDelitel : array[0..N] of boolean;
i,p : integer;
begin
p:=2; //prvni prvocislo
repeat
{krok 1: oznacim vsechny nasobky prvocisla p}
i:=p+p;
while i<=N do begin
MaDelitel[i]:=true;
i:=i+p;
end;
{krok 2: najdu dalsi prvocislo}
p:=p+1;
while MaDelitel[p] {tedy neni to prvocislo} do p:=p+1;
until p*p>N; // a to cele opakuji....
//ted spoctu pocet prvocilel od 2 do N
p:=0;
for i :=2 to N do if not MaDelitel[i] then p:=p+1;
Writeln('Existuje ',p,' prvocilsel <= ',N);
Readln;
end.
Důleľitá poznámka: Pro přehlednost vyuľívá algoritmus triku a to, ľe se spoléhá na vynulování globálních proměnných. (Je to oprávněný předpoklad, ale pokud bychom z hlavního programu učinili proceduru, přestane fungovat! Museli bychom přidat vynulování pole MaDelitel[]. ) Po skončení hlavní smyčky repeat-until můľeme hodnoty v poli nějak vyuľít. V příkladu se spočte, kolik prvočísel je od 2 do N.
Můľeme ale hodnoty vypsat, uloľit do souboru a následně si i vykreslit obrázek. Zde je například nakresleno relativní zastoupení prvočísel v intervalu 2..N:
Obrázek byl vykreslen následující řadou povelů pro program gnuplot:
gnuplot> set data style lines
gnuplot> set logscale x
gnuplot> plot 'SeznamPrvocilsel.Dat'
using 1:($0+1)/($1-1)
$1 zde znamená hodnotu čísla v prvním sloupečku (soubor obsahuje jen jeden sloupeček) a $0 je pořadové číslo hodnoty (ta první má samozřejmě pořadové číslo 0).Vąimněte si, ľe v intervalu 2..3 je 100% prvočísel.
Typ záznam
Struktorovaný typ se skládá z menąích kousků, podobně jako strukturovaný příkaz se skládá z "menąích" příkazů, jednoduchých i strukturovaných (for for if). V případě pole byly jednotlivé kousky stejného typu a přístup k nim jsme měli pomocí indexace. V Pascalu máme ale jeątě jednu moľnost.
type tVectorXYZ = record
x,y,z : real;
end;
var a,x : tVectorXYZ;
begin a.x := 1; a.y := -1; a.z := 0; x := a; x.x := 2;
...
end.
Podobně jako u polí můľeme
Je libo pole záznamů nebo záznam s poli?
Samozřejmě můľeme kombinovat podle uváľení obě konstrukce a designátory nabyvaji na kráse:
type tComplex = record
Re,Im : real
end;
tCV3 = array [1..3] of tComplex;
tRGB = packed record
R,G,B : byte;
end;
tKomlexniPuntik
= record
x : tCV3;
barva : tRGB;
end;
var A : tKomlexniPuntik ;
b : tRGB;
...
A.x[2].Im := 0; A.x[1].Re := -1;
...
Inicializované proměnné a konstanty.
Dokud jsme pracovali jen s jednoduchými proměnnými, nebyl problém na začátku programu napsat pár přiřazení a inicializovat obsah proměnných. Pole nebo záznmay ale mohou být deląí a jejich inicializace sérií přiřazovacích příkazů by byla nepohodlná. Mohou nastat dva případy
A) hodnoty je třeba inicializovat před výpočtem a ty se
jiľ nemění.
B) hodnoty je třeba inicializovat před výpočtem, a ty se
poté budou dále měnit.
K tomu můľeme pouľít následující konstrukce se syntaxí:
DeklaraceIniKonstProm: (var | const)
Ident : Typ =
IniKonstVyraz ';'
IniKonstVyraz: KonstVyraz | '('
SeznamIniKonstVyrazu ')'
SeznamIniKonstVyrazu: IniKonstVyraz (','
IniKonstVyraz)*
a zde jsou příklady s inicializovanými poli :
const iFaktorial : array [0..12] of integer = (1,1,2,6,24,120,720,5040,40320,
362880,3628800,39916800,479001600);
var ObjemNadob[1..PocetNadob] = (0,0,10);
CisloKroku : integer = 0;
Konstrukce výrazu typu pole je dovolen jen v deklaraci inicializované proměnné nebo typované konstanty, do přiřazovacího příkazu nemůľeme pouľít
ObjemNadobi:=(1-x,x,y); ObjemNadobi:=(0,0,11);
Pozor, některé dřívějąí verse jazyka Pascal neumějí variantu s var a i proměnné se deklarují jako const.
type tSeznamAz10Cisel
= record
Pocet : 0..10;
Cisla : array [1..10] of integer;
end;
var Dlouhy : tSeznamAz10Cisel = (Pocet : 8; Cisla : (1,2,3,4,5,6,7,8,0,0) );
Kratky : tSeznamAz10Cisel = (Pocet : 2; Cisla : (1,2,0,0,0,0,0,0,0,0) );
Samozřejmě můľeme inicializovat i jednoduché proměnné.
var Oddelovac : char = ',';
CisloKroku : integer = 0;
Proměnné z vícenásobná deklarace jako třeba
var a,b : char ;
nemohou být inicilizovány. Neinicializované globální proměnné jsou při startu programu inicializovány na 0 (a to i tehdy, kdyľ 0 nepatří do jejich intervalu atp.), zatímco lokální proměnné obsahují před prvním pouľitím smetí. Typované konstanty smí být lokální (tedy deklarovány v bloku nějaké procedury či funkce), inicializované proměnné nikoli a jsou bohuľel dovoleny jen na globální úrovni.
Variantní záznam
Někdy chceme ukládat jednotlivé poloľky přes sebe. To proto, ľe význam má jen jedna z nich a rezervovat místo na ty ostatní je zbytečné. Předpokládejme, ľe si chceme udělat pořádek v plechových geometrických součástkách na naąem skladu. Taková plechová součástka je popsaná materiálem, tlouą»kou plechu, tvarem a rozměry. Rozměry trojúhelníku se ale určují pomocí tří čísel zatímco u kruhu stačí jen poloměr.
program CaseTest;
type
tTvar = (tvObdelnik, tvTrojuhelnik, tvKruh);
tMaterial = (mtHlinik,mtOcel);
tPlechovyUtvar = record
Material:tMaterial;
Tloustka:Real;
case Druh:tTvar of
tvObdelnik: (Vyska, Sirka: Real);
tvTrojuhelnik: (StranaA, StranaB, StranaC: Real);
tvKruh: (Polomer: Real);
end;
function Obvod(W:tPlechovyUtvar):real;
begin
if W.Druh=tvObdelnik then Obvod:=2*(W.Vyska+W.Sirka);
if W.Druh=tvTrojuhelnik then Obvod:=W.StranaA+W.StranaB+W.StranaC;
if W.Druh=tvKruh then Obvod:=W.Polomer*2*Pi;
end;
Cvičení: dodělejte funkce pro plochu, objem a hmotnost součástek.
Endiáni: (J. Swift)
Cvičení: Pomocí variantního záznamu prozkoumejte proměnnou typu integer jako pole 4 bytů. Je zřejmé, ľe pokud do celého čísla typu integer uloľíte hodnotu 1, pak ve třech bytech bude 0 a v jednom 1, o tom říkáme, ľe je nejméně výnamný. Zjistěte jestli váą počítač ukládá nejméně významý byte na nejniľąí nebo naopak nejvyąąí adrese. (Předpokládmáme ovąem, ľe pole se ukládá vľdy tak, ľe s rostoucím index roste i adresa uloľení.)
Alignment a packed record (array)
V současných počítačích je vyzvednutí hodnoty proměnné z paměti, které musí předcházet libovolné operaci s proměnnou, velmi náročnou operací, např. ve srovnání s časem potřebným pro sečtení dvou celých čísel. Aby se urychlila práce počítače, vyzvedává více bytů najednou, řekněme ľe 8. Pro optimální běh programu je pak vhodné, aby procesor dokázal načíst např. celé číslo (4 byty) na jedinou operaci přístupu do paměti. Nejjednoduąąím řeąením tohoto problému je, ľe kaľdá poloľka záznamu o velikosti 4 byty začíná na adrese dělitelné 4 a podobně pro proměnné velikosti 8 bytů. To znamená, ľe se v pamě»ovém prostoru pro uloľení záznamu nacházejí nevyuľitá místa. Konkrétní způsob uloľení je nejlépe vyzkoumat experimentálně, protoľe je dán pouľitým překladačem. Někdy můľe být plýtvání opravdu velké:
type rec_brb = record
a:byte; //tady nasleduji 7 práznych bytů
j:real;
b:byte; //tady nasleduji 7 práznych bytů
end;
rec_bb = record
a:byte;
b:byte;
end;
...
Writeln( sizeof(rec_brb) ); // --> 24
Writeln( sizeof(rec_bb) ); // --> 2
Tedy pro uloľení 10 bytů informace, pouľil překladač 24 bytů pamě»ového prostoru. To jsme zjistili pouľitím universální funkce sizeof, která jako parametr akceptuje identifikátor typu nebo proměnnou libovolného typu (jde jakoby o předávání odkazem, takľe ne libovolný výraz) . Vrátí pak počet bytů, který proměnná či typ zabírá.
Zabránit takovémuto zarovnávání (angl.: alignment) můľeme pouľitím klíčového slova packed v deklaraci typu.
type rec_brb = packed record
a:byte;
j:real;
b:byte;
end;
Tentokrát bychom dostali velikost záznamu 10 byte.
I naskládání poloľek v poli můľe být ze stejných důvodů plýtvavé. Proto i před slovem array se můľe nacházet slovo packed, pokud chceme zařídit aby se ąetřilo místem.
Typ Text
Wirthův Pascal odráľel jeątě nerozvinutý obor skladování dat té doby. Pro praktické pouľití souborového systému, který nám OS nabízí, můľeme samozřejmě pouľít přímé volání sluľeb OS. Pro představu tady je zjednoduąená hlavička knihovnou Windows exportované funkce pro zápis dat:
function WriteFile(hFile: integer; // uchopitko (cislo) souboru
const Buffer; // data
nNumberOfBytesToWrite: integer; // kolik zapsat
var lpNumberOfBytesWritten: integer): boolean;
Nad podobnými funkcemi, které v podstatě nabízejí jen různé formy stěhování binárních dat mezi soubory a proměnnými, máme jiľ od ranných verzí jazyka TurboPascal k dispozici také prostředky pro práci s datovými a textovými soubory na úrovni jazyka Pascal. Stále ale kdyľ pracujeme se souborem, musíme respektovat, ľe je to objekt spadající do kompetence OS a v jazyce máme jen vrátka, skrze která nám je dovoleno provádět se soubory uľitečné operace pohodlněji, mnohá omezení vąak zůstávají.
Nejdříve budeme uvaľovat vstup z a výstup do textového souboru. Dnes jiľ je jakýkoli textový soubor posloupností bytů, nikoli ątítků či bloků na pásce nebo magnetickém bubnu. Textový soubor je soubor, ve kterém, co byte to znak nebo řídící znak. (Pozn. byte ve smyslu nejmenąího kvanta zapsatelného do souboru, 8 bitů, nikoli jako předdefinovaný typ ObjectPascalu pro krátké neoznaménkované číslo.) Poslední dobou ani to jiľ není tak prosté háčky, čárky a hyeroglyfy vąech národů se spojily v Unicode a tak příątí generace studentů programování bude muset překousnout 16-bitové znaky! Pokud neplatí jednoduchá rovnost co byte (word) to znak, mluvíme souboru binárním. Příkladem můľe být třeba soubor nějakého obrázku: Nehomogenní skládačka z binární hlavičky souboru následované bloky, kaľdý se svojí hlavičkou a komprimovanými daty .... Práci s takovým souborem si necháme na jindy.
V Pascalu je textový soubor (tedy klíč od oněch ony dveří do světa) zastoupen proměnnou typu Text. Takto vytvoříme (nebo pokud existuje zkrátíme na nulovou délku) textový soubor s názvem 'Soubor.txt' v běľném adreáři a zapíąeme do něj krátkou zprávu:
var T: Text; begin Assign(T,'Soubor.txt'); Rewrite(T); Writeln(T,'Toto je prni radek souboru, druhy zustane prazdny!'); Close(T); end.
Co se souborem můľeme dělat nám velmi určuje OS, on je za něj zodpovědný. Proto i proměnné representující soubory zdědí jistá omezení. Předevąím, je zakázáno přiřazení do proměnné typu Text. Navíc nemá pro nás přístupnou vnitřní strukturu, takľe nemůľeme psát něco jako T.Name := 'Soubor.txt'. Zbývá tak jen třetí způsob práce s proměnnou typu Text, a to pouľití této proměnné jako parametr procedury nebo funkce. I zde jsme omezeni, nesmíme předávat soubor hodnotou. Proto vąechny oprace se soubory budou mít formu volání procedur, kde jako první parametr bude proměnná typu Text. Následujícími procedurami, které podobně jako třeba ReadLn umí překladač aniľ se musíme doproąovat nějaké knihovny, můľeme ovládat práci s textovými soubory.
Assign(TextVar, Retezec) ... Přiřazení jména.
Musíme zadat platné jméno na daném stroji.
Rewrite(TextVar) ... Vytvoř soubor nulové délky a otevři
pro zápis. Pokud existuje zahoď co je v něm.
Append(TextVar) ... Otevři soubor pro zápis na jeho konci.
Připisuje se za původní obsah. Musí existovat.
Reset(TextVar) ... Otevři soubor pro čtení. Musí před
tím existovat.
Close(TextVar) ... Uzavři soubor.
Mezi voláním Rewrite a Close (případně Append a Close) můľeme psát do soubor pomocí příkazů Write a Writeln, viz výąe uvedený příklad. Mezi voláním Reset a Close můľeme ze souboru číst pomocí Read a ReadLn.
Pokud se vyskytne problém dostaneme buď
Runtime error 2 at 0040432E
nebo o něco hezčí okénko s oznámením, ľe se nám
počítač a tvůrci programu omlouvají....
Jak víme chování se dá v případě chyby ovlivňovat
pomocí direktiv. Jako obvykle, máme na výběr mezi krátkou a
dlouhou formou:
Samo od sebe (default) je hlídání nastveno na {$I+} t.j.
{$IOCHECKS ON} a dostaneme výąe uvedené chování.
V případě, ľe je hlídání "vypneme" {$I-} t.j.
{$IOCHECKS OFF}, pozastaví se vykonávání operací vstupu a
výstupu aľ do doby, neľ se na zeptáme funkce
function IOResult : integer; // je k dispozici vľdy, nepotřebujeme ľádnou knihovnu
Ta nám vrátí 0, pokud nenastaly problémy. Pokud vrátí něco jiného, znamená to ľe nastaly problémy a podle hodnoty se můľeme dohadovat, co se stalo. Předevąím jsou ale od okaľiku volání IOResult opět povoleny operace se soubory.
Pokud tedy chceme např. vědět, zda nějaký soubor existuje, můľeme výąe uvedeného chování vyuľít a psát
function SouborExistuje(const Jmeno) : boolean;
var T:text;
begin
{$IOCHECKS OFF}
Assign(T,Jmeno);
Reset(T); // pokud není, vznikne chyba a pozastaví se daląí operace
Close(T); // nesmíme zapomenout, kdyby existoval
SouborExistuje := IOResult=0;
{$IOCHECKS ON}
end;
Jak tuąíme, důvody proč nám OS nedovolí ze souboru číst můľou být různé a výąe uvedená funkce opravdu jen testuje jestli je operace Reset pro daný soubor povolena. Pokud potřebujeme detilnějąí informace o souboru, nezbyde neľ se zeptat OS přímo.
Příkazy Write a WriteLn
Obecně se vyskytují ve dvou variantách:
Write(PromTypuSoubor, Vyraz, ...)
nebo
Write(Polozka, ...)
V prvním případě je první parametr proměnná typu Text a výstup probíhá do přísluąného souboru, jeho obsah je tentýľ jaký v druhém případě skončí na standardním výstupu (konsoli, přesměrovaný někam...).
Jak vidíme Write a Writeln nejsou obyčejné procedury a nemají ani obyčejné parametry. Předevąím jich mohou mít libovoný počet výrazů mnoha typů (celočíselné, reálné, řetězce, znaky, logické). Dále za výrazem mohou následovat i dva daląí celočíselné výrazy oddělené od toho prvního dvojtečkami, které určují formát výstupu, tedy způsob, jímľ se hodnota převede to textové podoby. Za první dvojtečkou se nachází ąířka pole, do níľ je třeba hodnotu vypsat. Pro reálné výrazy můľe za druhou dvojtečkou následovat počet desetinných míst.
Vyzkouąejte jak se chovají následující příkazy textového výstupu.
Writeln(Pi); Writeln(Pi:5); Writeln(Pi:10); Writeln(Pi:15); Writeln(Pi:20); Writeln(Pi:25);
Writeln(Pi); Writeln(Pi:30); Writeln(Pi:30:0); Writeln(Pi:30:4); Writeln(Pi:30:8); Writeln(Pi:30:12); Writeln(Pi:30:16); Writeln(Pi:30:20); Writeln(Pi:30:24);
Podobně můľeme psát
Write('':i);
a vypsat tak i-krát mezeru.
Writeln je znám dobrou vůlí vypsat výstup i kdyľ se hodnota nevejde do předepsané ąířky. V tom případě se vypíąe v minimální nutné ąířce. Bohuľel to větąinou přílią nepomůľe:
for i := 995 to 1005 do Writeln(i:4,i*i:7,i*i*i:10); vypíąe 995 990025 985074875 996 992016 988047936 997 994009 991026973 998 996004 994011992 999 998001 997002999 100010000001000000000 100110020011003003001 100210040041006012008 100310060091009027027 100410080161012048064 100510100251015075125
Pro daląí strojové zpracování jsou asi data stejně nepouľitelná i kdyľ se Write tak moc snaľil.
Příkazy Read a ReadLn
Fukce slouľí (opět ve dvou variantách) ke čtení ze
standardního vstupu nebo z textového souboru. Ve druhém
případě musí být první parametr typu text.
Protoľe procedura Readln vľdy po načtení vąech parametrů
přeskočí na začátek nového řádku,
vyzkoumáme. coz následujícího vstupu skočí ve kterých
proměnných dále uvedených příkladů
1 2 3 4 5
10 20 30
Budeme uaľovat dva kousky kódu.
Read(a,b); // a=1 b=2 Read(c); // c=3 zbytek se nepouľije
a
ReadLn(a,b); // a=1 b=2 zbytek řídku se přeskočí ReadLn(c); // c=10 Naproti tomu pro vstupní data ve formě
1 2 3 4
se výsledky obou kousků kódu liąit nebudou.
Samozřejmě podobně je to s načítáním hodnot reálných
proměnných, formát zatím popíąeme příklady
1
+1
-1
1.23
1E10
1E+10
1.003E-10
atp. dle libosti, ovąem
1.00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000E10
si ale vyloľí jako 1.0 takľe vąeho s mírou.
Read/Readln ale umí načíst i řetězce a například následující kód načte do pole celý textový soubor
program ReadText;
var T : array of string;
i,s : integer;
begin
SetLength(T,100);
i:=-1;
while not eof do begin
i:=i+1;
if (i>High(T)) then SetLength(T,2*i);
Readln(T[i]);
end;
SetLength(T,i+1);
// ted spoctu pocet znaku, abych uz s tim nactenym souborem neco udelal
s := 0;
for i := 0 to High(T) do s:=s+length(T[i]);
Writeln('Soubor obsahuje ',s,' znaku na ',High(T)+1,' radcich');
Readln;
end.
Pokud jej spustíme a jako vstup mu přesměrujeme nějaký deląí textový soubor, dozvíme se, ľe
C:\Projects\prog\pokusy>test<"C:\Program Files\Borland\Delphi6\Source\Rtl\Win\Windows.pas" Soubor obsahuje 1113550 znaku na 30848 radcich
Poznámka: Pokud Předěláte SetLength(T,2*i) na SetLength(T,i+1) zjistíte, ľe je program pro soubor s 30000 řádky nepracuje, ale jen rachtá diskem. Jakkoli jsme zatím tomu tak neříkali, program vytváří dynamické datové struktury a my naráľíme na nejvlastnějąí problémy dynamických datových struktur, tzv. potřebu sběru odpadků. [...Pár slov na přednáące.. Čtěnáře poznámek odkazuji na pokračování přednáąky.] Tak jak je program napsán nepřesáhnou odpadky po zvětąování pole dvojnásobek velikosti uľitečných dat pro uloľení informací o řádcích (+100), coľ můľeme na naąí neinformatické úrovni povaľovat za dostatečný úspěch.
Pro základní vstup číselných hodnot jsou pouľitelné přímo procedury Read/ReadLn. Pro sloľitěji formátovaný vstupní text je nejjednoduąąí si vstup načíst do řetězce, v něm nalézt polohu číselného podřetězce a ten převést na číslo pomocí funkce val. Viz velký příklad na řetězce výąe. Za zmínku stojí, ľe narozdíl od běhové chyby nebo mechanismu oznamování chyb přes IOResult, umí val vrátit přímo index znaku, který mu zabránil v převední řetězce na číslo a oąetření případné chyby tak můľe být méně drsné.
Strukturované příkazy With a Case
Příkaz With
Účel příkazu with vysvětlí nejlépe příklad.
type tComplex = record
Re,Im : real
end;
var z : tComplex;
Re: Real;
...
Re := 1; with z do begin Re := 0; Im := 1; end; Writeln (Re,' ',x.Re);
Vypíąe ' 1.00000000000000E+0000 0.00000000000000E+0000', protoľe unvitř příkazu with přestala být vnějąí proměnná Re vidět a byla zakryta identifikátorem sloľky záznamu z.
Příkaz Case
je příkaz, který jsem doposud tajil. Občas se ale hodí nahradit řadu podmíněných příkazů např.
if n=0 then f:=1 else if n=1 then f:=x else if n=2 then f:=x*x else if n=3 then f:=x*x*x else if n=4 then begin f:=x*x; f:= f*f; end; else begin f:=exp(ln(x)*n); end;
následujícím strukturovaným přikazem
case n of 0: f:=1; 1: f:=x; 2: f:=x*x; 3: f:=x*x*x; 4: begin f:=x*x; f:= f*f; end; else f:=exp(ln(x)*n); end;
Část začínající else lze vynechat a také můľeme místo jednoho čísla psát seznam čísel a intervalů, které se ale nesmějí překrývat
case c of '-': n:=-n; 'a'..'z','_': n:=n+1; 'A'..'Z', '0'..'9','$': n:=n-1; end; // kód nemá ľádný význam
Pole s volným koncem - zaráľka
V mnoha případech neznáme v okamľiku kdy píąeme program, kolik hodnot bude v poli potřeba uskladnit. Běľným řeąením je odhadnout shora maximální rozumný počet a pole dimenzovat na tuto maximální zátěľ. Jde o velmi běľný postup a i některé solidní programy (TeX) vám někdy nahlásí, ľe jste vyčerpal kapacitu a musíte si program překompilovat s větąí konstantou určující kapacitu polí pro uskladnění.
Jak ale do takovéhoto pole naskládat seznam s proměnnou délkou. Prvním řeąením je pouľití zaráľky. Jde o to, ľe za posledním uloľeným prvkem nastavíme ten daląí na nějakou dohodnutou hodnotu, jeľ nás upozorní, ľe jiľ nejde o data ale o oznámení konce. V kódu pak procházíme pole dokud nenarazíme na zaráľku. Pokud je procházení pole součástí zamýąleného kódu, nepřidá kontrola na zaráľku přílią práce a není ani přílią náročnějąí neľ si pamatovat rovnou počet údajů v poli. Technologie zaráľky se běľně pouľívá u jednoho typů polí: řetězců. Zatímco Pascal s implementací řetězců nejdříve otálel, jiný jazyk jeho éry, C, který musel od počátku slouľil pro psaní skutečných programů, rozhodl, ľe dnes je nejčastějąím způsobem uloľení řetězců takzvaný zero-terminated string. Nejčastějąím proto, ľe dneąní OS mají kdesi na počátku právě operční systém, kvůli jehoľ psaní si K&R vymysleli jazyk C. Proto aľ budeme potřebovat komunikovat na niľąí úrovni s OS, budeme se muset spokojit s touto nejjednoduąąí formou řetězce. V následujícím příkladu poľádáme OS ( = Windows, konkrétně) aby nám sputili (angl. execute) program ping. Ten bez paramtrů vypíąe nápovědu a skončí. Proceduře zajią»ující komunikaci s OS, WinExec, musíme předat parametr právě jako nulovou zaráľkou ukončené pole znaků. Proceduru WinExec nalezneme exportovanou v knihovně (UNIT) Windows, která exportuje 4373 funkcí, 92 procedur a 180typů, které můľete pouľít ke komunikai s aplikační vrstvou OS a jeho nadstaveb (tím se má říci, ľe kdyľ blufujeme o počítačích, hodí se rozliąovat v pro nás monolitním "OS" vlastní OS, nadstavby, vnitřnosti,...).
program pokus;
uses Windows;
var cmd : array[0..1234] of Char;
i : integer;
begin
cmd := 'ping'; // Nějaký "příkaz" reprezentovaný exe-souborem, nikoli copy či dir
WinExec(cmd,1);// Řekni OS aby příkaz vykonal
Sleep(1000); // Za 1000 ms by to uľ mohlo být hotovo, WinExec totiľ nečeká
i := 0; // Příklad velmi jednoduché práce znak po znaku
while cmd[i]>#0 do begin
writeln(cmd[i]);
i:=i+1;
end;
readln;
end.
V cyklu while je vidět
jednoduchý příklad na operaci s kaľdým znakem nulou
ukončeného řetězce. Příkaz
cmd:='ping'
ukazuje daląí z výjimek
v kompatibilitě typů. Stručně je shrneme na konci
přednáąky. Zde jen, ľe by se to nepřeloľilo, kdyby byl typ
pole např. array[1..1234] of
Char, tedy tyto nejen nulovým
znakem ukončené (vlastnost uloľení dat) ale i nulovým
indexem počínající jsou (důleľitá formalita).
Pozor, zaráľka je jen jedna. Kdyľ ji přehlédnete, mohou za
ní následovat beľné znaky a na daląí zaráľku uľ v poli
vůbec nemusíte narazit, index tak překročí hranice pole a
mohou se začít dít věci.
Cvičení: Napiąte vnitřnosti následujících procedur:
type tStrZ = array[0..1024] of Char; procedure SpojRetezce(const A,B: tStrZ; var AaZaNimB: tStrZ); function DelkaRetezce(const A: tStrZ) : integer; procedure KusRetezce(const A: tStrZ; OdKterehoZnaku,KolikZnaku: integer; var VybranuKusA: tStrZ);
Pole s volným koncem -
proměnná pro délku
Je zřejmé, ľe místo abychom na určení délky řetězce
měli zvláątní funkci, která jen počítá počet znaků
před zaráľkou, můľeme přidat jeątě proměnnou, která
bude vľdy říkat, kolik hodnot máme v poli
uloľeno.
Typické pouľití je v následujícím kódu: Kdyľ uľ umíme
ukládat řadu hodnot do pole, můľeme si ukázat jak tato data
načteme z klávesnice.
{$RANGECHECKS ON}
const Max = 1000;
var PocetHodnot : integer = 0; //inicializovaná proměnná
Hodnoty : array[1..Max] of real;
x : real;
begin
Writeln('Zadejte aľ ',Max,'kladných reálných čísel');
Writeln('Zadávání ukončete záporným číslem nebo nulou.');
ReadLn(x);
while x>0 do begin
PocetHodnot := PocetHodnot + 1;
Hodnoty[PocetHodnot] := x;
ReadLn(x);
end;
Writeln('Načetl jsem ', PocetHodnot, ' čísel. Příątě s nimi i něco udělám');
end.
Takto obvykle vypadají programy z učebnic zpracovávající vstup dat . Jde o to načíst řadu čísel, něco s ní udělat (v naąem případě jsme je jen naskládali do pole), přičemľ konec vstupu je indikován nějakým číslem mimo rozsah povolených hodnot. Jakkoli jsme tedy odstranili zaráľku z naąeho popisu dat uvnitř programu, zůstala tu stále zaráľka jako konečník vstupních dat.
Poprvé je zde pouľita funkce ReadLn k něčemu lepąímu neľ jen k čekání na stisk klávesy Enter. Jde o vylepąenou versi proceury Read, která umí načíst ze vstupu (nebo souboru, to uvidíme později) data několika základních typů: Celé číslo, reálné číslo, jeden znak a řetězec znaků (uvidíme dále). ReadLn pak jeątě přečte a zahodí vąechny znaky do konce řádku včetně. Naproti tomu Read pokračuje tam, co skončila.
Pole s volným koncem - proměnná pro délku a pole sbalené do záznamu
Proměnné Hodnoty a PocetHodnot jsou úzce svázány a zvláątě ta první bez druhé není pouľitelná. Mohlo by nás napadnout spojit je do jednoho záznamu a chápat je jako jednu (strukturovanou) proměnnou.
type tHodnoty = record
Pocet : integer;
Data : array[1..Max] of real;
end;
Víme, ľe Pascal s nově definovaným typem přílią zacházet neumí, nezbude nám, neľ si pro něj napsat sadu procedur a funkcí a nebo jednoduąe psát Hodnoty.Data[Hodnoty.Pocet]. V situaci, kdy náą program musí zacházet s několika různě dlouhými seznamy dat můľe spojení k sobě přísluąných dat a metadat do jedné struktury zvýąit pohodlí a bezpečí.
Pole s otevřeným koncem (dynamická pole)
Námi pouľívaná verse Pascalu nám umoľňuje jeątě lepąí řeąení:
program DynArrTest;
var Hodnoty : array of real;
x : real;
kam : integer;
begin
Writeln('Zadejte libovolný počet kladných reálných čísel');
Writeln('Zadávání ukončete záporným číslem nebo nulou.');
ReadLn(x);
while x>0 do begin
Kam:=High(hodnoty)+1; //Low(Hodnoty) je 0
SetLength(Hodnoty,Kam+1);
Hodnoty[Kam] := x;
ReadLn(x);
end;
Writeln('Načetl jsem ', High(hodnoty)+1, ' čísel. Tady jsou jejich druhe mocniny:');
for kam := 0 to High(hodnoty) do
Writeln(Hodnoty[Kam],sqr(Hodnoty[Kam]));
readln;
end.
Od předeąlého se program hlavně liąí tím, ľe pole Hodnoty má jako spodní mez intervalu indexů nulu. Počet prvků pole můľeme měnit procedurou SetLength(Pole,JakDlouhe). Aktuální horní mez zjistíme pomocí funkce High. Dolní mez si můľeme zjistit s pomocí funkce Low, ale bude to vľdy nula a nelze ji měnit. Funkce Low a High můľeme pouľít i pro běľná pole, ale tam nám vrátí konstantu danou přísluąnou mezí intervalu indexu, a můľe to být třeba i znak, kdyľ je má přísluąné pole typ indexu char.
Následující program má být varováním, ľe při volání funkce SetLength mohou přestat platit odkazy na původní prvky pole.
program PozorNaNe; type tCA = array of Char; var A,B : tCA ; Procedure UdelejDveVeci(var X : tCA; var c:char; N : integer); begin SetLength(X,N); X[0]:='A'; c:='X'; // tady je ten prusvih, c uz nemusi odkazovat na spravne misto. end; begin SetLength(A,10); SetLength(B,10); UdelejDveVeci(A,A[0],10); Writeln(A[0]); UdelejDveVeci(A,A[0],100); // Nejspis staci 13 Writeln(A[0]); // Uz to pise 'A' readln; end.
Pokud bychom kromě SetLength(X,N) měnili jeątě velikost jiných polí, mohlo by se stát, ľe paramtr c nebude odkazovat do prázdna jako nyní, ale přiřazení c:='X' naruąí některé z těchto polí, které po změně velikosti skočilo na pamě»ovém místě původního pole A.
Pole s otevřeným koncem jako formální parametr
pokud deklarujeme formální parametr typu array of real tak jako v následujícím příkladu, můľeme při volání předat jako hodnotu
program test;
type tDP = array of real;
var b : array[char] of real;
c : tDP;
function Soucet(const V:array of real) :real;
var i : integer;
s : real;
begin
s:=0;
for i := low(V) to high(V) do s:=s+V[i];
Soucet:=s;
end;
begin
Writeln(Soucet(b)); // vypíąe 0 nebo» statické pole je inicializováno na 0
Writeln(Soucet(c)); // vypíąe 0 nebo» dynamické pole nemá na počátku ani jeden prvek
Writeln(Soucet([0,1,2])); // vypíąe 3
Readln;
end.
Je třeba roszliąit jeden malý rozdíl mezi předchozími dvěma příklady. V prvním byl parametr typu tCA a ąlo tak o dynamické pole. Pro něj je definována operace SetLength. Naproti tomu v druhém případě byl typ formálního parametru array of... . Z minula víme, ľe formální parametr typu array [interval] of NejakyTyp, není povolen, proto6e by nebyl komaptibilní s ľádnou proměnnou a proceduru by nebylo moľno vůbec pouľít. Formální parametr typu array of je tedy moderní konstrukcí určenou k tomu aby bylo moľno funkci předat pole s nějakým základním typem ale libovolnými mezemi. S dynamickými poli se shoduje v tom, ľe Low vrací vľdy 0, i kdyľ definiční interval byl třeba 1..3 nebo 'a'..'z'. High je tak rovno (délka_pole - 1).
Řetězce
Zatím jsme pouľívali řetězce jen na komentování výsledků v příkazech Writeln. Řetězce, tedy pole znaků, mohou ale slouľit k lecčemu a některé z úloh formulovaných zcela přirozeně pro řetězce jsou, nahlíľeno okem informatiků, docela sloľité. Jako rekreaci doporučuji si prohlédnout třeba nějakou literaturu k hledání nejdeląího společného podřetězce dvou řetězců, úlohu, která můľe být docela uľtečná třeba u analýzy DNA. Právě pro rozsáhlost problému budeme řetězce studovat jen velmi utilitárně a vyhneme se mnoha detailům a problémům.
Řetězcové konstanty
Jiľ víme vąe o znacích a řetězce jsou
speciální pole znaků. Protoľe by bylo nepříjemné psát
něco jako
('A','h','o','j',' ','l','i','d','i','!')
lze v Pascalu zapisovat řetězcové konstanty takto 'Ahoj
lidi!'.
Writeln('''Apostrof uvnitr retezce ('') se pise jako dva ('''')''');
Vypíąe: 'Apostrof uvnitr retezce (') se pise jako dva ('')'
Typ String
Naneątěstí přes vąechnu snahu o pravidelnost v Pacsalu se ukázalo, ľe uľitečné věci jsou nepravidelné. Příkladem jsou třeba řetězce. Jde o sloľitý problém. Jiľ jsme viděli, ľe kvůli spolupráci s OS mají speciální význam pole znaků se spodní mezí intervalu indexů 0. Z historických důvodů je jazyce Object Pascal připraveno několik variant řetězcových typů. Povíme jen něco málo o typu string.
var s,t : string;
i,j : integer;
begin
s := 'ABCD1234'; {Přiřazení konstanty do řetězce}
t := s; {Přiřazení hodnoty s do t}
Writeln(t); {Vypíąe 'ABCD1234'}
t := copy(s,2,3); {Přiřazení výsledku funkce do proměnné, kus počínaje druhým dlouhý tři}
t[1] := 'B';
Writeln(t); {Vypíąe 'BCD'}
Delete(s,1,4); {Vypustí 'ABCD'}
Writeln(s); {Vypíąe '1234'}
t := '..'+s; {Sloľení řetězce z kousků}
Writeln(t); {Vypíąe '..1234'}
Insert('xx',t,2);
Writeln(t); {Vypíąe '.xx.1234'}
Writeln('Retezec '''+t+''' ma delku ',Length(t)); {délka řetězce ve znacích}
Writeln('Podretezec ''23'' se nachazi na indexu ',
Pos('23',t), {nalezení polohy podřetězce jinak 0}
' retezce '+t);
Setlength(t,20);
t[20]:='6';
Writeln(t); {Vypíąe '.xx.1234 6' ale ty mezery nejsou mezery, jak uvidíme:}
for i:=1 to length(t) do
Write('#',ord(t[i]));
{Vypíąe '#46#120#120#46#49#50#51#52#0#0#0#0#0#0#0#0#0#0#0#54'); }
str(Pi:20:10,s); {Nacpi Pi do retezce}
Writeln(#10#10#10#10+s); {čtyři novéřádky a Pi}
val(copy(s,11,10),i,j); {převeď řetězec na číslo}
Writeln(i); {Vypíąe 1415926536}
Readln;
end.
Jeątě máme po ruce daląí spoustu procedur a funkcí např. UpperCase
Velmi důleľitá je někdy funkce
procedure Val(S; var V; var Code: Integer)
která umí do celočíselné nebo reálné
proměnné V dosadit hodnotu zapsanou v řetězci. Code je 0
pokud nenastanou problémy, jinak je to index problematického
znaku v řetězci.
Interně je typ string podobný poli znaků s otevřeným koncem,
první znak řetězce (pokud má délku >0) se ale nachází
na indexu 1. Proto SetLength(Retezec,Delka)
znamena výjimečně, ľe pouľití Retezec[Delka]
je OK.
Proceduru SetLength(Retezec,Delka) pouľijeme předevąím tehdy, pokud chceme pomocí indexů pracovat s jednotlivými znaky řetězce (buď vědomě za jeho aktuální délkou, nebo ji jednoduąe nezáme). V rámci přiřazovacího příkazu a při volání systémových funkcí pracujících s řetězci tuto funkci folat smozřejmě nemusíme.
Ve výjimečných případech se můľe hodit vědět, ľe řetězec s neproměnnou délkou se deklaruje jako
type tJmenaReckychPismen = string [10]; //zadne neni delsi
Jde ale o přeľitek z minulosti, třeba jen tím, ľe v hranatých závorkách smíme uvést jen číslo do 255.
Reálná funkce v tabulce
Budeme se zbývat situací, kdy z nějakého důvodu musíme mít funkci v počítači uloľenou jako tabulku hodnot. Bohuľel jeątě pár let nebude moľné psát array[real] of real a tak budeme graf funkce parametrizovat celočíselným parametrem z nějakého intervalu. To uľ v Pascalu jde
type tIndexTabulky = 0 .. 12;
tPolicko = array[tIndexTabulky] of real;
const HodnotyX : tPolicko = (-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5);
HodnotyY : tPolicko = (-1.3734008, -1.3258177, -1.2490458, -1.1071487, -0.78539816,
0, 0.78539816, 1.1071487, 1.2490458, 1.3258177, 1.3734008);
Pokud bychom jedno z polí nahradili explicitní funkcí indexu, stále bychom mluvili o určení funkce pomocí tabulky.
Malujeme funkci z tabulky
Jiľ víme, ľe pokud vytvoříme přesměrováním standardního výstupu (kam píąe běľně Writeln) soubor se dvěma sloupečky čísel, můľeme program gnuplot poľádat, aby za nás namaloval pěkné obrázky. V minulé přednáące jsme se ale naučili pracovat se soubory, řetězci a dokonce spouątět jiné programy a tak můľeme vąechnu tuto práci automatizovat.
Následující modul nám pomocí dvou funkcí, které exportuje, umoľní malovat grafy z puntíků a lomených i kulatých čar. Modul je záměrně co nejkratąí, aby bylo jeho funkci moľno vysvětlit na přednáące.
Unit GnuPlot01;
Interface
Procedure MalujPole(const x,y : array of real; const Jmeno:string; const format:string = 'notitle with lines');
Procedure ZobrazGraf(const Jmeno : String; const Rozsah: String = '');
Implementation
USES windows;
{$IOCHECKS OFF}
const GnuPlotExe = 'C:\Program Files\gnuplot\wgnupl32.exe';
Procedure MalujPole(const x,y : array of real; const Jmeno:string; const format:string = 'notitle with lines');
var T : text;
S,PP : String;
nxy,i,index,j,ipos : integer;
const Big = 100000;
begin
nxy := High(X);
assert( nxy = High(Y) );
i:=1;
while (i<=length(Jmeno)) and (Jmeno[i]='>') do i:=i+1;
S := copy(Jmeno,i,Big);
if i<=2 then begin
{Pripad 'Soubor' nebo '>Soubor'}
{Nejdrive prikaz pro vykresleni}
Assign(T,S+'.plt');
Rewrite(T);
Writeln(T,'plot "'+S+'.dat" index 0 '+format);
Writeln(T,'pause -1');
Close(T);
{Potom otevrit soubor pro vystup dat}
Assign(T,S+'.dat');
Rewrite(T);
end else begin
{pripad '>>Soubor'}
{nactu Predchozi Prikaz do PP}
Assign(T,S+'.plt');
Reset(T);
if IOResult=0 then begin
Readln(T,PP);
Close(T);
end else
PP:='';
Rewrite(T);
if PP='' then
{Ted vyrobim prikaz pro vykresleni}
Writeln(T,'plot "'+S+'.dat" index 0 '+format)
else begin
{Tady vylepsim prikaz pro vykresleni}
j:=1;index := -1;
repeat //zjistit posledni index
ipos := pos(' index ',copy(PP,j,Big));
index := index+1;
j := j+ipos+7;
until ipos=0;
Writeln(T,PP,',"',S,'.dat" index ',index,' ',format);
end;
Writeln(T,'pause -1');
Close(T);
{Potom otevrit soubor pro vystup dat}
Assign(T,S+'.dat');
Append(T); if IOResult>0 then Rewrite(T); //velmi hrube....
Writeln(T);
Writeln(T); //Pred data pridam dva radky aby to byl dalsi blok pro gnuPlot
end;
for i := 0 to nxy do Writeln(T,x[i],#9,y[i]);
Close(T);
if IOResult<>0 then MessageBox(0, 'MalujPole: Chyba pri zapisu do souboru','Chyba',MB_OK);
end;
Procedure ZobrazGraf(const Jmeno : String; const Rozsah: String = '');
const WinExecMaxKodChyby = 31;
var CmdStr : string;
T : Text;
begin
CmdStr := GnuPlotExe + ' ' + Jmeno + '.plt';
if Rozsah<>'' then begin
{ musim prikaz
>plot "soubor" with ...
zmenit na
>plot [Range] "soubor" with ...}
Assign(T,Jmeno + '.plt');
Reset(T);
Readln(T,CmdStr); //Nacti puvodni prikaz pro gnuplot
Assert(Copy(CmdStr,1,5)='plot ');
Insert(Rozsah,CmdStr,5);{Sem ^ strcit Rozsah}
Close(T);
Assign(T,Jmeno + '.tmp');
Rewrite(T);
Writeln(T,CmdStr);
Writeln(T,'pause -1');
Close(T);
CmdStr := GnuplotExe + ' ' + Jmeno + '.tmp';
end;
// !! Trik !!
// 1. Delphi umeji prevest String na (ukazatel na) PoleZnakuSeZarazkou napiseme-li tam PChar
// 2. SW_NORMAL pripadne SW_MAXIMIZE rikaji jak ma vypadat okenko grafu
if WinExec(PChar(CmdStr),SW_NORMAL) <= WinExecMaxKodChyby
then MessageBox(0, 'MalujPole: Nenalezen WGnuPl32.exe','Chyba',MB_OK);
end;
{ ToDo:
- kontrola spravnosti poradi formatu
- moznost nastavit styl car
- etc. chybi sposta veci jde zamerne o jednoduchy kod
}
end.
Triky pouľité v kódu byly probrány na přednáące a jsou v kódu komentovány.
Podrobně byla probrána i struktura modulů a to, jak vyčlenit z hotového programu recyklováníhodné kusy a jak z nich vytvořit modul rozdělením na veřejné rozhraní a privátní implementační část. Čtenáře poznámek odkazuji na [Satrapa], kapitola 20.
Význam obou funkcí nejlépe objasní Příklady pouľití
begin MalujPole(HodnotyX,HodnotyY,'Priklad'); // MalujPole(HodnotyX,HodnotyY,'Priklad','title "Data" with points pointtype 2 pointsize 2'); // MalujPole(HodnotyX,HodnotyY,'>>Priklad','title "Lomene cary" with lines'); // MalujPole(HodnotyX,HodnotyY,'>>Priklad','smooth csplines title "Splajny"');
ZobrazGraf('Priklad');
end.
Význam kontrolních slovíček with points atp. je v povídání o gnuplotu a určitě jeątě dodám nějakou tabulku příkladů příkazů plot v gnuplotu, aby bylo jasné, co přesně se z gnuplotu máte učit.
Interpolace
V výąe uvedeném případě je rozloľení hodnot nezávislé proměnné x rovnoměrné, tzv. ekvidistantní. Velmi často se s hodnotami takto rovnoměrně poskládanými setkáme u veličin měřených v závislosti na čase (např. vzorky zvuku na CD...) Data v proměnných HonotyX a HodnotyY můľeme znázornit grafem
Jak máme ale určit funkční hodnotu mezi jednotlivými body grafu? Co třeba proloľit sousedními body úsečky?
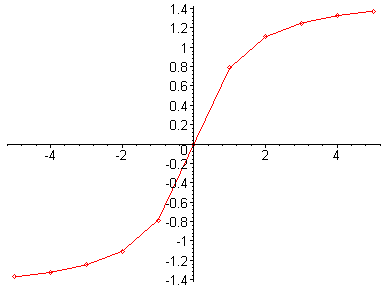
Vidíme, ľe výsledek není přílią dokonalý, ale přesto
Cvičení: (důleľité) napiąte funkci, která mi pro reálné x v rozsahu -3 .. 3 vrátí takto vypočtenou hodnotu a bude mít hlavičku např.
function FzTabulky(x : real) : real;
a namalujte její graf. Pokud se ke cvičení dostanete později, nezapomeňte, ľe v uspořádaném poli se dá hledat velmi rychle.
Pokud se nám tato hranatá funkce nezdá dost dobrá, můľeme zkusit lepąí. Víme, ľe N+1 body můľeme proloľit právě jeden polynom N-tého stupně, takľe máme hned kandidát. A kolika body budeme polynom prokládat? No přece vąemi, kdyľ uľ je máme. Tady je výsledek:
®e nevypadá stále dost dobře? No tak zkusíme někde sehnat víc bodů a to musí pomoci
Nepomohlo...
Přes toto počáteční varování jsou polynomiální
interpolace velmi uľitečné, a tak si o nich povíme více.
V příkladu byla ale pouľit lehce zákeřná funkce arcustangens
a navíc aspoň uprostřed intervalu vypadá výsledek hezky.
Předevąím problém je lineární a tak stačí zjistit jak vypadá funkce proloľená implusem a tu pak oąkálujeme a sečteme přes vąechny vzorky. Takto vypadá impuls v x=5:
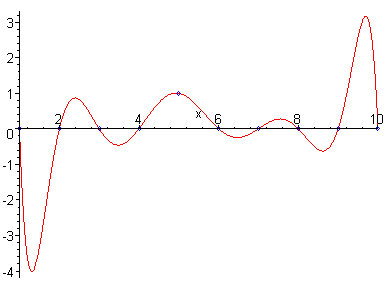
Funkce proloľená vyznačenými puntíky bude určitě úměrná polynomu
Y5(x) = (x - 1)(x - 2)(x - 3)(x - 4)(x -
6)(x - 7)(x - 8)(x - 9)(x - 10)
Pokud ji vydělíme Y5(5) máme funkci na obrázku.
Takovouto úvahou dostáváme Lagrangeův interpolační vzorec
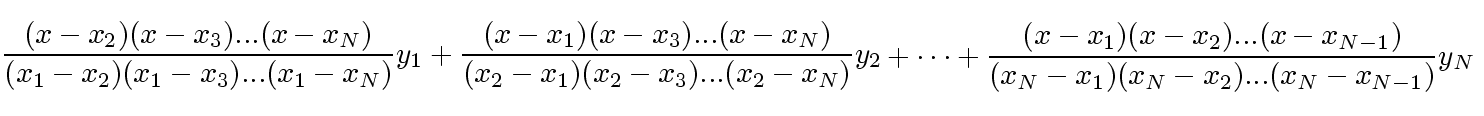
Pokud si povąimneme jmenovatelů, tak vidíme, ľe pro obecné
rozloľení bodů xi
budeme muset provést N*(N-1) násobení. Protoľe ale není
důvod předpokládat, ľe N bude nabývat nějakých
závratných výąek, nemluvíme zde ani tak o náročnosti
výpočtu jako o faktu, ľe kód bude obsahovat dva cykly.
Samozřejmě existují i jiná schémata pro výpočet
interpolace.
Cvičení: Kromě obecné procedury pro interpolaci polynomem obecného stupně, si zkuste napsat některou z řady uľitečných interpolačních funkcí jako např:
function Interp2(x, x1,x2,y1,y2 : real) : real; function Interp3(x, x1,x2,x3,y1,y2,y3 : real) : real;
atp. které určitě někde vyuľijeme.
Příklad:
toto je funkce pro výpočet interpolované hodnoty přímo z Lagrangova vzorečku:
function LInterp(t:real; const X,Y : array of real):real; var i,j,n : integer; s,f : real; begin n := High(X); {assert( n = High(Y) ); tam dame az budeme vedet co to je} s := 0; for i := 0 to n do begin f:=1; for j := 0 to n do if i<>j then f := f*(t-X[j])/(X[i]-X[j]); s := s+f*Y[i]; end; LInterp := s; end;
přičemľ jde o přímý přepis vzorečku, bez jakýchkoli triků.
Polynomy jako pole koeficientů
Protoľe teď umíme spočíst fuknční hodnotu polynomu proloľeného body Xi,Yi, můľeme chápat tuto dvojici vektorů také jako zápis polynomu. Obvyklé ale polynomem rozumíme spíąe pole jeho koeficientů.
Následující program ukazuje jak definujeme pro takový polynom základní operace a jak je můľeme pouľít ke konstrukci koeficientů interpolačního polynomu. Jde o rozdílné obou přístupy a nakonec vykreslíme jejich rozdíl. (Komentář: Spočíst nejdříve koeficienty interpolovaného polynomu a pak pouľívat Hornerovo schéma k výpočtu hodnot interpolované funkce není nejlepąí.)
Program Lagr2;
Uses GnuPlot01;
type tPolynom=array of real;
{
Pozor formalni parametry funkci jsou typu array of real
a nikoli tPolynom, abych mohl psat
W := SoucinPolynomu(A,[-1,0,1]); pro W:=(x^2-1)*A
}
Function HodnotaPolynomu(const P:array of real;x:real): real;
var s : real;
i : integer;
{Spocte funkcni hodnotu polynomu pomoci Hornerova schematu}
begin
s := P[High(P)];
for i := High(P)-1 downto 0 do s:=s*x+P[i];
HodnotaPolynomu := s;
end;
Function KopiePolynomu(const P:array of real): tPolynom;
var Q : tPolynom;
i : integer;
begin
SetLength(Q,High(P)+1);
for i := 0 to High(P) do Q[i]:=P[i];
KopiePolynomu := Q;
end;
Function SoucetPolynomu(const A,B:array of real): tPolynom;
var Q : tPolynom;
i,n : integer;
s : real;
begin
n:=High(A);
if nj then f := SoucinPolynomu(f,[-X[j]/(X[i]-X[j]),1/(X[i]-X[j])]);
s := SoucetPolynomu(s,f);
end;
InterpolacniPolynom := s;
end;
function LInterp(t:real; const X,Y : array of real):real;
var i,j,n : integer;
s,f : real;
begin
n := High(X);
assert( n = High(Y) );
s := 0;
for i := 0 to n do begin
f:=1;
for j := 0 to n do if i<>j then f := f*(t-X[j])/(X[i]-X[j]);
s := s+f*Y[i];
end;
LInterp := s;
end;
const N = 12;
type tIndexTabulky = 0 .. N;
tPolicko = array[tIndexTabulky] of real;
const HodnotyX : tPolicko = (-3,-2.5,-2.0,-1.5,-1.0,-0.5, 0,0.5,1.0,1.5,2.0,2.5,3.0);
var HodnotyY : tPolicko ;
const M = 1000;
var iX,iY,iDelta : array [0..M] of real;
var i : integer;
var xa,xb:real;
IP : tPolynom;
begin
HodnotyY[6]:=1;
MalujPole(HodnotyX,HodnotyY,'Hodnoty','title "Data" with points pointtype 2 pointsize 2');
//MalujPole(HodnotyX,HodnotyY,'>>Hodnoty',' smooth cspline title "cspline"');
// nyni spoctu nejdriv interpolacni polynom
IP := InterpolacniPolynom(HodnotyX,HodnotyY);
// potrebuji vzit nasledujici rozsah promenne x
xa := HodnotyX[Low(HodnotyX)];
xb := HodnotyX[High(HodnotyX)];
// a do poli nacpu hodnoty x_i a y_i = IP(x_i)
for i :=0 to M do begin
iX[i] := xa + i/M*(xb-xa);
iY[i] := LInterp(iX[i],HodnotyX,HodnotyY);
iDelta[i] := HodnotaPolynomu(IP,iX[i])-iY[i];
end;
MalujPole(iX,iY,'>>Hodnoty','title "Lagrange" with lines');
MalujPole(iX,iDelta,'Rozdily','title "Chyba IP" with lines');
ZobrazGraf('Hodnoty','[][-1:2]');
ZobrazGraf('Rozdily');
{ Nasledujici prikaz nas muze presvedcit, ze problem je ve vypoctu polynomu:
Writeln(HodnotaPolynomu(IP,-3),' ',LInterp(-3,HodnotyX,HodnotyY));
readln;
}
end.
Cvičení: Vyzkouąejte jaké obrázky program vykreslí. Měňte počet bodů a prokládané funkce a pozorujte co se stane.
Cvičení: V jedné z minulých přednáąek jsme pouľili rekurentní vztah pro Legendrovy polynomy. Zkuste jej pomocí funkcí uvedených v programu pouľít k výpočtů koeficientů Pn(x).
Cvičení: Jak je to s přesností pro polynomy vyąąího řádu. Porovnejte podobně jako ve výąe uvedeném programu pro interpolace.
Matice
Doposud jsme uvaľovali předevąím pole s jedním indexem. V Pascalu, jak víme, ale můľeme psát
type tMatice3x3 = array[1..3,1..3] of real; var A : tMatice3x3 ... A[3,1] := ...
Protoľe jsme si definovali nový typ, musíme pro praktické pouľití definovat procedury a funkce.
function Det3x3(const A:tMatice3x3) : real; begin Det3x3 := A[1,1]*A[2,2]*A[3,3] + A[1,2]*A[2,3]*A[3,1] + A[1,3]*A[2,1]*A[3,2] - A[1,1]*A[2,3]*A[3,2] - A[1,2]*A[2,1]*A[3,3] - A[1,3]*A[2,2]*A[3,1] ; end;
Často se ale stane, ľe rozměry matic v programu jsou jsou různé. Dokonce se můľe stát, ľe jeden program pracuje chvíli s maticemi 3x3, za chvíli 14x14 a za daląí chvíli 100x100 atd. V takovém případě bychom museli mít 3 různé funkce pro determinat, tři pro sčítání matic, tři pro násobení atd.
Naątěstí můľeme matici chápat jako pole řádků a tak pouľít deklaraci
type tVektor = array of real;
tMatice = array of tVektor;
Oproti přednáące z algebry nazýváme
vektory řádky matice, takľe pozor. To proto, ľe chceme aby
matice z Algebry
[a11 a12 a13]
[a21 a22 a23]
[a31 a32 a33],
přeąly na matice
A[0,0] A[0,1] A[0,2]
A[1,0] A[1,1] A[1,2]
A[2,0] A[2,1] A[2,2]
Pokud by se někomu chtělo, můľe obětovat nulté prvky polí
a nulté řádky matic a mít indexy počínající jedničkou.
Pro velká N budeme matici konstruovat přímo programem, ale pro niľąí hodnoty bychom mohli chtít zapsat matici takto:
A := [ [0 ,1 ,1-x],
[1+x,y ,1 ],
[1 ,x ,y ] ];
Bohuľel toto zatím Pascal neumí, ale pokud si definujeme vhodné funkce, následující zápis je v pořádku:
A := _m([_v([ 0 , 4 , 0 ]),
_v([1-x, 0 ,1+x]),
_v([ 0 , y , 8 ])] );
Podle nálady, můľe jít o přijatelnějąí variantu série přiřazení:
A[0,0]:=0; A[0,1]:= 4; A[0,2]:= 0; A[1,0]:=1-x;A[1,1]:= 0; A[1,2]:= 1+x; A[2,0]:=0; A[2,1]:= y; A[2,2]:= 8;
ve které je ale velmi snadné poplést indexy.
Uľ s vektory se daly dělat věci (Cvičení:
zkuste si napsat proceduru pro Gramm-Schmidtovu ortogonalizaci) a
v případě matic nemáme ąanci ani povrchně probrat ty
nejzákladnějąí operace (a to ani z pohledu potřeb budoucího
uľivatele nějaké knihovny pro práci s maticemi).
Cvičení: Po prostudování pouľití matic v níľe uvedeném
programu pro Gauss-Jordanovu eliminaci zkuste napsat operace
násobení a sčítání matic.
Řeąení soustavy lineárních rovnic (Gaussova - Jordanova eliminace)
Mějme soustavu 4 rovnic pro 4 neznámé:
9y + 6z + 4w = 3 2x + 3y + 4z = 3 x - 3z + 2w = 0 x + 4y + 4z - w = 1
Tato soustava se běľně representuje maticí

Protoľe matici budme chtít upravit na
diagonální tvar, kde nenulové prvky budou jen na diagonále,
musíme nejdříve prohodit první dva řádky
(tedy první dvě rovnice, to jistě smíme):

Nyní první řádek (tedy rovnici) vydělíme
tak aby na diagonále zbyla jednička - normalizace

Nyní od druhého aľ čtvrtého řádku odečteme
vhodný násobek prvního řádku tak aby v prvním
sloupci mimo diagonálu zbyly nuly (lineární kombinace rovnic
je OK):

Teď jiľ stručně - normalizace 2. řádku
(nic nemusíme prohazovat)

odečtení násobků druhého řádku
Normalizace 3.řádku

Odečtení násobků 3. řádku od ostatních

Normalizace 4. řádku

Konečně, odečtení násobků čtvrtého řádku

Připoměňme, ľe tato matice representuje lineární systém
x = 3/4
y = 23/2
z = -33/4
w = -51/4
Celá metoda tak postupně opakuje tři kroky: podmíněné
prohození řádků, normalizaci řádku a
eliminaci nediagonálních elementů daného sloupce.
Technický detail: je zvykem prohazovat řádky tak,
aby se na diagolále objevil v absolutní hodnotě nejjvyąąí
pouľitelný (řádek>=sloupec) člen daného sloupce. To ľe
nestačí jen kontola na 0 tak aby ąel řádek normalizovat je
zřejmé, i číslo 10^-15 by nám vadilo (vyzkouąejte). To ľe
se vyplatí najít právě v absolutní hodnodě největąí
prvek je uľ numerická matematika.
Následuje program, ve kterém je také procedura pro GJ
eliminaci. Současným výpočetm pro N pravých stran se spočte
inverzní matice (taková aby M M^(-1) = JednotkovaMatice).
Program Maticni;
uses Sysutils;
{Pouzivame assert a ten v Delphi-IDE neni videt bez SysUtils}
type tVektor = array of real;
tMatice = array of tVektor;
function _v(const a : array of real) : tVektor;
{Udela z pole realnych cisel vektor}
var b : tVektor;
i : integer;
begin
SetLength(b,High(a)+1);
for i :=0 to High(a) do b[i] := a[i];
_v:=b;
end;
function _m(const a : array of tVektor) : tMatice;
{udela z pole vektoru matici}
var b : tmatice;
i : integer;
begin
SetLength(b,High(a)+1);
for i :=0 to High(a) do begin
Assert(High(a[i])=High(A[0]),'_m: Matice musi byt obdelnikova!');
b[i] := a[i];
end;
_m:=b;
end;
Procedure WriteM(const M : tMatice;W:integer=9;D:integer=5);
var r,s : integer;
begin
for r:=0 to High(M) do begin
for s:=0 to High(M[r]) do Write(M[r,s]:W:D);
Writeln;
end;
end;
Function IdentM(N:integer):tMatice;
var Q : tMatice;
r,s: integer;
begin
SetLength(Q,N,N);
for r:=0 to N-1 do
for s:=0 to N-1 do
if r=s then Q[r,s]:=1 else Q[r,s]:=0;
IdentM:=Q;
end;
Function TranspM(const A:tMatice):tMatice;
var Q : tMatice;
N,M,r,s: integer;
begin
N := High(A);
M := High(A[0]);
SetLength(Q,M+1,N+1);
for r:=0 to M do
for s:=0 to N do
Q[r,s]:=A[s,r];
TranspM:=Q;
end;
function GJElim(const A,B: tMatice): tMatice;
{Samozrejme resi A.x_i=b_i pro vice pravych stran}
{Cviceni: zkuste funkci pretizit a pridat dalsi pro jedinou pravou stranu}
var M,Z : tMatice;
t : tVektor;
r1,r,s,N,L,rmax : integer;
u : real;
begin
N := High(A); // rozmery ctvercove matice A
L := High(A)+High(B)+1;
Assert(N = High(A[0]),'GJElim: Matice musi byt ctvercova!');
Assert(N = High(B[0]),'GJElim: Vektory v B musi byt spravne dlouhe!' );
{1. A a B spojime do jedine matice}
SetLength(M, N+1{x},L+1);
for r := 0 to N do {radek}
for s := 0 to N do {sloupec}
M[r,s] := A[r,s];
for r := 0 to N do
for s := 0 to High(B) do
M[r,s+N+1] := B[s,r];
{2. Gauss-Jordanova eliminace}
for r := 0 to N do begin{pro vsechny radky}
{2.1 Najdi nejvetsi |prvek| v r-tem slopecku na radcich r..N}
rmax := r;
s := r; {v r-tem sloupecku, ze}
for r1 := r+1 to N do if abs(M[r1,s])>abs(M[rmax,s]) then rmax:=r1;
{2.2 Prehod r-ty a rmax-ty radek}
if r<>rmax then begin
t := M[r];
M[r] := M[rmax];
M[rmax] := t;
end;
{2.3 Normalizuj radek r}
u := M[r,r];
Assert(u<>0,'GJElim: Matice neni regularni');
for s := 0 to L do begin
M[r,s] := M[r,s]/u;
end;
{2.4 odecti od ostatnich radku r-ty*A[r,s] }
for r1:=0 to N do if r<>r1 then begin
u := M[r1,r];
M[r1,r]:=0;
for s := r+1 to L do
M[r1,s]:=M[r1,s]-u*M[r,s];
end;
end;
{3. Vratit vysledek}
SetLength(Z,High(B)+1,N+1);
for r := 0 to N do
for s := 0 to High(B) do
Z[s,r]:=M[r,s+N+1];
GJElim := Z;
end;
Function InvM(const M:tMatice):tMatice;
begin
InvM:=TranspM(GJElim(M,IdentM(High(M)+1)))
end;
var M : tMatice;
begin
M := _m([_v([ 0, 4, 0]),
_v([ 2, 0, 0]),
_v([ 0, 8, 8])] );
WriteM(M);
Writeln;
WriteM(InvM(M));
Readln;
end.
{ A takto si můľeme vyzkouąet, zda funguje transpozice
WriteM(_m([_v([ 11, 12, 13]),
_v([ 21, 22, 23])] ) );
Writeln;
WriteM(TranspM( _m([_v([ 11, 12, 13]),
_v([ 21, 22, 23])] ) ));
Writeln;
}
Časová a pamě»ová náročnost algoritmu
Vezměme jednoduchý obrázek
tuąíme, ľe věci se zesloľití, pokud vezmeme větąí počet vrcholů
co můľeme říci o chování pro velký počet vrcholů (47)?
a takto vypadá detail

Nech» počet vrcholů je N. Pak se můľeme například ptát
Podobně se můľeme ptát třeba
Stejně tak nás můľe zajímat kolik paměti bude program potřebovat.
Pro kaľdý problém zkusíme najít charakteristické N číslo udávající jeho velikost. Ne vľdy je to moľné ale pro představu pár příkladů:
Počet poloľek na skladu v programu pro skladové
hospodářství.
Počet neznámých v soustavě lineárních rovnic.
Počet jednání které má vyřídit obchodní cestující.
Počet souborů, které chceme efektivně vypálit na cédéčka.
Nyní se můľeme ptát jak se bude program zabývající se výąe uvedenými problémy chovat při růstu onoho charakteristického čísla N. Samozřejmě, pokud neplánujeme růst skladu, zvyąování počtu neznámých atp., nemusíme se tím zabývat. I ve fyzice se ale projevuje tendence počítat sloľitějąí a sloľitějąí problémy (třeba ty jednoduąąí uľ někdo vyřeąil) a tak na problém velkého N můľeme narazit.
Při porovnávání různých algoritmů máme moľnost porovnat, jak se chovají pro různé velikosti vstupních dat přímo
Někdy závisí doba řeąení problému na konkrétních vstupních hodnotách, často ale, jak jsme viděli, u soustav lineárních rovnic, závisí pouze na velikosti problému.
Vzpomeneme-li si na definici algoritmu, víme ľe jde o posloupnost elementárních operací. Předpokládejme nejdříve, ľe elementárními operacemi rozumíme základní operce jako jsou sčítání, násobení, větvení, přístup k jednoduché proměnné, přístup k prvku pole volání či návrat z podprogramu atp. Změříme-li dobu, kterou potřebuje počítač k provedení kaľdé z těchto operací a budeme-li předpokládat, ľe celý program se vykoná za dobu odpovídající součtu těchto jednotlivých operací, víme jak spočíst dobu potřebnou k provedení programu. Řekněme třeba, 6e podprogram pro skalární součin dvou vektorů
Function SkalSoucin(const A,B:tVektor):real; var i:integer; begin s:=0; for i:=0 to High(A) do s:=s+A[i]*B[i]; SkalSoucin := 0; end;
provede následující operace (časy jsou z dobrých důvodů jen přibliľné a konkrétní hodnoty nedůleľité, mysleme si ale, ľe časy jsou v nanosekundách nebo, jeątě lépe, v tiknutích hodin procesoru počítače).
| Operace | Čas | Počet | Celkem |
| Předávání parametrů | 4 | 1 | 4 |
| Vynulování proměnné | 2 | 1 | 2 |
| Zjiątení horní meze pole A | 30 | 1 | 30 |
| Příprava cyklu | 6 | 1 | 6 |
| Načetní A[i] | 3 | N | 3N |
| Přinásobení B[i] | 6 | N | 6N |
| Přičtení s | 6 | N | 6N |
| Uloľení do s | 4 | N | 4N |
| Zvětąení i | 2 | N | 2N |
| Skok na začátek cyklu | 6 | N-1 | 6N-6 |
| Přiřazení do výsledku | 4 | 1 | 4 |
| Návrat z funkce | 10 | 1 | 10 |
a tedy celkový čas T = 27 N + 50.
Podobně bychom pro násobení matice vektorem dostali třeba
T = 36 N^2 + 44 N +26
Pokud nás ale zajímá chování pro větąí N, je rozhodující první člen. Píąeme
T ~ 36 N^2
Určit koeficient přesně je ale velmi obtíľné a asi jedinou moľností je aľ analýza měření závislosti času výpočtu na N. Pokud chceme mluvit o výkonu algoritmu v okamľiku jeho návrhu jeątě před jeho kódováním a nákupem počítače, ukazuje se, ľe nejjednoduuąí je prostě psát
T = O(N^2)
Velké O(f) je označení pro libovolnou takovou funkci g, která splňuje vztah
0 < lim | g / f | < nekonečno pro N jdoucí do nekonečna
Následující tabulka má ilustrovat, ľe opravdu rozhodující je právě řád, nikoli konkrétní hodnota koeficientu u vedoucího členu.
| N | N.log2 N | N^2 | N^3 | 2^N | N! |
| 3 | 6 | 9 | 27 | 8 | 6 |
| 10 | 30 | 100 | 1 000 | 1 024 | 3 628 800 |
| 30 | 150 | 900 | 27 000 | 1.1 E9 | 2.65 E32 |
| 100 | 700 | 10 000 | 1 000 000 | 1.27 E30 | 9.33 E157 |
| 1 000 | 10 000 | 1 000 000 | 1 E9 | 1.1 E 300 | 4.02 E2567 |
| 10 000 | 140 000 | 100 000 000 | 1 E15 | 2.0 E3010 | 2.84 E35659 |
Mimochodem, od velkého třesku uplynulo asi 3x10^26 nanosekund.
Vztah O(f) . O(g) = O(f . g) nám pak umoľňuje místo rozkladu algoritmu na elementární kroky O(1), uvaľovat strukturovaně.
Třeba Gauss-Jordanova eliminace (za předpokladu, ľe počet
pravých stran je <=O(N) ) pro kaľdý řádek ( tedy O(N) krát)
provádí
# hledání největąího prvku na/pod diagonálou O(N)
# normalizace O(N)
# odečtení násobku řádku od vąech ostatních O(N^2)
A na začátku a na konci jeątě nějaké kopírování O(N^2)
Odsud máme
O(N^2) + O(N)*( O(N)+ O(N)+ O(N^2)) = O(N^3)
V tabulce si pak snadno najdeme, pro jaká N jde o zelený, oranľový či hnědý problém.
Podobně jako se s rostoucím N nějak chová čas potřebný k provedení výpočtu, nějak rostou i pamě»ové nároky. Protoľe nad velikostí datových struktur máme trochu lepąí kontrolu, lze v praxi velmi dobře odhadnout co se vejde a co ne. V rozvahách o schůdnosti různých algoritmů ale také často vystačíme s notací velkého O.
Seznamy a jiné lineární datové struktury
Mimo jiné si zde ukáľeme, ľe má smysl mluvit o typickém
a nejhorąím moľném případě a jeho
časové náročnosti.
Netříděný seznam
| Jmeno='Pavel' Teplota=36.5 |
Jmeno='Martin' Teplota=37.5 |
Jmeno='Jan' Teplota=36.9 |
Jmeno='Hugo' Teplota=39.5 |
Jmeno='Igorl' Teplota=37.2 |
Jmeno='Ivo' Teplota=37.1 |
| Přístup přes index..... | O(1) |
| Přidání poloľky | O(1) |
| Ubrání poloľky | O(N) |
| Nalezení poloľky | O(N) |
Seřazený seznam
| Jmeno='Hugo' Teplota=39.5 |
Jmeno='Igorl' Teplota=37.2 |
Jmeno='Ivo' Teplota=37.1 |
Jmeno='Jan' Teplota=36.9 |
Jmeno='Martin' Teplota=37.5 |
Jmeno='Pavel' Teplota=36.5 |
| Přístup přes index | O(1) |
| Přidání poloľky | O(N) |
| Ubrání poloľky | O(N) |
| Nalezení poloľky podle klíče.... | O(log(N)) |
| Nalezení poloľky obecně | O(N) |
Komentář: Nejlepąí, nejhorąí a typický případ pro operaci přidání.
Cvičení: napiąte proceduru, která v
seřazeném seznamu hledá pomocí půlení intervalu a ukaľte,
ľe časová náročnost je O(log(N)).
Poznámka: toto je důleľitý návod jak hledat v tabulkách funkčních hodnot pokud nejsou hodnoty nezávislé proměnné rovnou ekvidistantní, kdy se dostáváme na O(1).
Asociativní pole
Jde o velmi zajímavou a důleľitou datovou strukturu. Základní idea po uľivatelské stránce je mít moľnost jako index pouľít místo pořadí rovnou klíč, třeba řetězec.
Bohuľel není moľné psát přímo
TeplotaPacienta := Pacineti['Pavel'].Teplota
a) protoľe to Object Pascal neumí b) protoľe není jasné jestli tam poloľka s klíčem 'Pavel' vůbec je
proto se přístup (vlastně vyhledání) podle klíče rodělí na dva kroky
1. Nalezení indexu k poloľce a ověření její existence
2. Vlasní přístup přes index
Trik spočívá v tom, ľe první operaci lze uskutečnit v čase O(1).
1. Nejprve se spočte hodnota tzv. matlací (hash) funkce,
která přiřadí klíči celé číslo. Tato funkce musí mít
velmi divokou závislost své hodnoty na klíči, rozhodně
nestačí součet hodnot znaků řetězce nebo něco jiného
jendoduchého, ale zároveň nesmí být výpočetně přílią
náročná.
hash('Pavel') --> 1249765812
2. Poté se spočte, kde by podle matlací hodnoty měla v poli
leľet hledaná hodnota
1249765812 mod VelikostPole ---> 7
3. Na indexu 7 se buď
a) nenachází nic
b) je tam hledaný prvek
c) je tam nějaký jiný prvek se stejnou hodnotou MatlaFce mod VelikostPole.
Pak se dějí věci, např. se prohlíľejí vąechny poloľky aľ do první prázdné, jestli není tam, kdyľ uľ bylo správné místo obsazené.
Důleľité je, ľe pokud Matlafunkce funguje správně, je nepravděpopdobné, ľe se v jednom políčku sejdou dvě poloľky a bude třeba řeąit kolizi, pokud máme pole dimenzováno, řekněme, třeba na dvojnásobek poľadované kapacity.
Podobně se přidává prvek, hned poté, co zjistíme jestli tam náhodou uľ není a nejde tedy jen o přepsání.
(Pozn. Hotovou máme v Delphi bohuľel jen strukturu (objekt) THashedStringList)
Více o asociativních polích se do přednáąky nevejde, je ale důleľité vědět, ľe informatici tuto strukturu promysleli a v případě potřeby máme k dipozici seznam následujících parametrů:
| Přístup přes index | O(1) |
| Přidání poloľky | O(1) |
| Ubrání poloľky | O(1) |
| Nalezení poloľky podle klíče.... | O(1) |
| Nalezení poloľky obecně | O(N) |
Pro fyzika nabízí tato struktura moľnost "keąovat" výsledky volání funkce.
Pokud výpočet funkce několika diskrétních parametrů trvá dlouho, můľe se vyplatit schovat si jiľ jednou vypočtené hodnoty. Narozdíl od funkce s jedním parametrem jako je faktoriál, kde si hodnoty schováme do pole a je to, musíme v tomto případě sáhnout po sloľitějąím řeąení. Parametry dohromady tvoří klíč. Ten zamatláme a podle matlacího indexu výsledek spolu s klíčem uloľíme v poli. Pokud pak potřebujeme znovu jiľ jednou spočtený výsledek, můľeme okamľitě zjistit, zda je jeątě k dispozici, nebo byla kolonka "keąe" přepsána. Obvykle totiľ kolize řeąíme zahozením původního obsahu. To jsme u seznamu nemohli. Pokud víme, ľe se stejné parametry opakují 10x na kaľdých 10 000 volání, víme, ľe hotovostní pamě» na 1000 výsledků nás vytrhne i kdyľ výsledky v okamľiku kolize v keąi zahazujeme.
Vnitřní třídění seznamu
Třídění = řazení.Vnitřní proto, ľe se odehrává uvnitř polovodičové části počítače a ne třeba na magnetické pásce.
Potřebujeme mít definovanou funkci <= dvou parametrů typu poloľky pole k setřídění. Část poloľky, která obsahuje informaci potřebnou pro porovnání se nazývá klíč. Obvykle z klíče nevyplývá přímo poloha v setříděném seznamu a má význam jen při porovnání s jiným klíčem.
Seznam povaľujeme za setříděný, platí-li
A1 <= A2 <= A3 <= ... <= AN
Uvaľujme tři příklady algoritmů pro třídění seznamu.
Třídění výběrem největąího prvku
Nejdříve najdeme mezi poloľkami 1..N tu největąí a
tu pak přehodíme s tou poslední.
Poté mezi poloľkami 1..N-1 najdeme tu největąí a tu dáme na
N-1 místo.
Atd. Algoritmus je viditelně O(N^2).
Třídění probubláváním
Spočívá v likvidaci vąech míst, kde nejsou výąe uvedené nerovnosti splněny. Seznam procházíme zdola nahoru a kdykoli narazíme na pár sousedních prvků seznamu, který nesplňuje pořadované řazení, oba prvky prohodíme. Kdyľ na ľádnou inverzi nenarazíme, je hotovo. Jde o sloľitějąí variantu předchozího, pravděpodobně inspirovanou magnetickými páskami a jinými sekvenčními zařízeními pro ukládání dat. Počet přehazování totiľ oproti minulé variantě výrazně stoupl, ale porovnávání i přehazovanání se odehrává blízko sebe.
Quicksort
je název algoritmu (Hoare cca 1960), který větąinou dokáľe seřadit seznam v čase O(N log N). Vyuľívá toho, ľe do přesné polohy poloľky mají nejvíce co mluvit ty sousední. Proto:
Potíľ spočívá v tom, ľe poloľku, podle které
rozdělujeme seznam na dvě části, vezmeme aniľ víme jestli
je blízko "prostředku". Proto se můľe stát, ľe pro nevhodně
uspořádaný vstup vezmeme vľdy tu nejmenąí/největąí a
skočíme u časové náročnosti O(N^2).
Cvičení: Vyzkouąejte si to napsat pro jednoduché pole čísel
a) pomocí rekurze b) pomocí zásobníku.
Motivace: Otevřete si stránku http://www.cs.ubc.ca/spider/harrison/Java/sorting-demo.html s prohlédněte si animace a porovnejte rychlost výąe uvedených algoritmů.Ty tam najdete pod názvy Selection Sort, Bubble Sort a Quick Sort.
Kód programu testujícího quicksort by mohl vypadat takto:
Program Sort;
procedure Quicksort(var A: array of real; l, r: Integer);
var i, j : Integer;
swp, rozhod: real;
begin
rozhod := A[(l + r) div 2];
i := l; j := r;
while i<j do begin
while (A[i] < rozhod) do i:=i+1;
while (rozhod < A[j]) do j:=j-1;
if i <= j then begin
swp := A[i]; A[i] := A[j]; A[j] := swp;
i:=i+1; j:=j-1;
end;
end;
if l < j then Quicksort(A, l, j);
if i < r then Quicksort(A, i, r);
end;
var data : array [0..220000 ] of real;
i : integer;
begin
for i :=0 to High(data) do data[i]:=random;
Quicksort(data,0,High(data));
for i :=1 to High(data) do if data[i-1]>data[i] then writeln('NESETRIDEN0');
Writeln('OK');
readln;
end.
Potíľ se tříděním dnes nespočívá v neznalosti algoritmu, ale v tom, jak naučit knihovní funkci, která třídění za nás obstará třídit data jejichľ strukturu sama nezná. O tom ale příątě.
Lineární datové struktury II.
Fronta
Tato datová struktur má jako prototyp sluľbu či
zařízení, které se stará o komunikaci pratiskárny s
prapočítačem. Prapočítač dokáľe vmľiku vygenerovat
poľadavek na vytisknutí tisíce znaků, ale pratiskárna jich
dokáľe vytisknout jen 50 za sekundu. Prapočítač stojí
tisíc dolarů za hodinu provozu, takľe se nemůľe zdrľovat
čekáním na pratiskárnu. Proto je tu něco, co vmľiku
spolyká výstupní data a pak je ve vhodném tempu předává
dál.
Jde tedy o datovou strukturu, která má řeąit problém, kdy jedna část programu chrlí data rychleji, neľ je jiná dokáľe zpracovávat, často je pak potřeba při komunikaci se světem, třeba v případě, ľe uľivatel mačká klávesy rychleji, neľ je stačí program zpracovávat.
Máme k dipozici tři operace: Vloľení, Výběr a Test na prázdnou frontu.
[] Uloľ(A) [A] Uloľ(B) [AB] Uloľ(C) [ABC] Vyber --> A [BC] Uloľ(D) [BCD] Vyber --> B [CD] Uloľ(E) [CDE]
atd.
Interně si fronta musí pamatovat, kde má hledat první a kam má přidat poslední prvek. Při realizaci v poli je z důvodů efektivity, tedy aby operace byly O(1), potřeba realizovat frontu tzv. kruhovým uloľením. Při dosaľení konce pole se daląí poloľka přidává na začátek, pokud odtud jiľ někdo zapsaná data vyzvedl. Abychom snadno rozliąili plnou a prázdnou frontu, je v tomto případě lepąí jako jednu ze stavových proměnných fronty pouľívat počet poloľek ve frontě. Pokud bychom pouľili index začátku a index konce, nebudeme moci přímočaře vyuľít celé pole pro frontu. Pokud má ploe délku 2^n stačí místo operace MOD jen laciný AND.
| X | X | X | X | ||
| A | X | X | X | ||
| A | B | X | X | ||
| A | B | C | X | ||
| X | B | C | X | ||
| X | B | C | D | ||
| X | X | C | D | ||
| E | X | C | D |
Pozn. V učebnicích programování často najdete úlohy, na procházení vąech stavů nějakého diskrétního systému. Třeba mnoho variací známé úlohy na přelévání vody je snadno řeąitlených, pokud si zavedeme podatelnu, kde uloľíme vąechny stavy, které můľeme z aktuálního dostat jedním přelitím a odkud si vľdy vyzvedneme jeden stav k daląímu přelévání. Podatelna je příkladem realizace fronty. Viz sbírky úloh z programování o tzv. prohledávání do ąířky, kde se také dozvíte různé moľnosti, jak si zapamatovat, ľe uľ jsme v daném stavu byli, coľ nám zaručí, ľe program skončí [Příklady z programování].
Jiným příkladem je nalezení nějakého souboru. Pokud by ąlo jen o jméno, je to natolik obvyklá oprace, ľe ji dokáľeme realizovat prostředky příkazové řádky:
dir /S/B | grep -i jmeno
(tedy poľádáme příkazem dir o vypsání vąech souborů v daném adresáři a jeho podadresářích a poté jeho výstup převezme program grep a ten se podívá jestli na nějakém řádku není řetězec "jmeno". Alespoň základní popis důleľitého programu grep snad stihneme na poslední přednáące.
Takovýto postup ale nepůjde roząířit na případ, kdy soubor, který hledáme nezle nalézt jen podle jména. Proto můľe nastat situace, kdy se budeme muset uchýlit k psaní programu. Ten by pak mohl vypadat takto (hledá se soubor délky 8274, na coľ je asi taky zbytečné psát program, ale ...) :
program Soubornik;
{Chcete-li program pouzit, vyhlednete si soubor dostatecne skryty
hluboko v nejakem podadresari a nastavte konstantu velikost}
uses Sysutils;
const dirsep = '\';
Velikost = 8274;
const VelikostPoleProFrontu = 1024;
var DelkaFronty : integer = 0;
PoleProFrontu : array[0..VelikostPoleProFrontu-1] of string;
KdeZacinaFronta : integer = 0;
procedure VlozDoFronty(const A:string);
var KamPsat : integer;
begin
assert(DelkaFronty<VelikostPoleProFrontu);
......
......
......
end;
function VyzvedniZFronty : string;
begin
assert(DelkaFronty>0);
......
......
......
end;
procedure SkonciJestliJeToOn(const Adresar: string;const F:TSearchRec);
begin
if F.Size = Velikost then begin
Writeln('Nasel jsem ho v adresari ',Adresar,' pod jmenem ',F.Name);
Readln;
Halt;
end;
end;
var F : TSearchRec;
Adresar : string;
begin
VlozDoFronty('C:\windows');
while DelkaFronty > 0 do begin
Adresar := VyzvedniZFronty;
if FindFirst(Adresar+DirSep+'*',faAnyFile,F)=0 then
repeat
if F.Name[1]<>'.' then begin // . a .. nechci
if (F.Attr and faDirectory)<>0 then VlozDoFronty(Adresar+dirsep+F.Name)
else SkonciJestliJeToOn(Adresar,F);
end;
until FindNext(F) <> 0;
FindClose(F);
end;
Writeln('Nenasel jsem ho');
readln;
end.
Rozmyslíme-li si funkci programu vidíme, ľe adresářový strom porhledáváme do ąířky.
Cvičení: Dopiąte vytečkované vnitřnosti procedur pro frontu řetězců.
Zásobník
Jedničkou mezi lineárními datovými strukturami je zásobník. Od prvopočátku počítačové doby se totiľ pouľívá pro řeąení otázky kam se má vrátit běh programu po ukončení podprogramu a v posledních desetiletích se také stará o postor a ľivot lokálních proměnných procedur.
Poznámka: (Rozpor idejí a reality): V matematice se
zavedla dvě značení pro operace s dvěma operandy:
1. Plus(A,B)
2. A Plus B
Protoľe ale operaci nemůľeme obecně uskutečnit dokud nemáme
k dispozici oba operandy, měl by být preferovaným zápisem
tento:
A B Plus
Např. 3+4*2 bychom přece měli psát jako
4 2 *
3 +
Podobně sice v Pascalu píąeme Secti(x,Soucin(y,z)), ale je
zřejmé ľe vąe probíhá jak je psáno výąe:
Ilustrace (na přednáące): Zásobník volání a vůbec jak v
principu probíhá předávání parametrů, volání funkcí a
alokace lokálních proměnných (bez konstrukce ebp-leseni /tzv.
stack frame/)
Ilustrace na přednáące: Vyhodnocení o něco sloľitějąího reálného aritmetického výrazu na zásobníkovém stroji (bez FPU registrů) ln(-x+sqrt(x**2++1))
Cvičení: Zásobník a prohledávání do hloubky - Změňte program pro hledání souboru tak aby prováděl hledání do hloubky. Napiąte dvě verze: jednu s explicitním zásobníkem, druhou jen s pouľitíme zásobníku volání tj. pomocí rekurse. Ze způsobu prohledávání adresářů je zřejmý název prohledávání do hloubky.
U datové struktury zásobník máme opět k dipozici tři operace: Vloľení, Výběr a Test na prázdný zásobník.
[] Vloľ(A) [A] Vloľ(B) [AB] Vloľ(C) [ABC] Vyber --> C [AB] Vloľ(D) [ABD] Vyber --> D [AB] Vloľ(E) [ABE]
Při realizaci v poli nám stačí jediná stavová proměnná a
snad to ani nejde napsat jinak neľ O(1).
Ilustace (na přednáące): prohledávání do hloubky, viz [Příklady z programování]
Pozn. Zásobník v dynamickém poli a jak často alokovat a proč ne pokaľdé SetLength.
Cvičení: Změňte minulý program aby porhledával adresářový strom do hloubky.
Malujeme obrázek (v Postscriptu)
Pro malování grafů funkcí pouľíváme jiľ několik týdnů program gnuplot. Vstupem pro tento program jsou tabulky čísel a výstupem hotový obrázek s osami, stupnicemi, barevnými křivkami atd.. Co kdyľ budeme chtít namalovat něco jiného neľ graf funkce, třeba následující obrázek:

Tuąíme, ľe bychom mohli zkusit najít vhodnou knihovnu (modul) a pak psát program který nám na obrazovku kreslí pomocí volání vhodných procedur, třeba
program Malovaci; uses KnihovnaProMalovani;
begin NamalujCaru(...); NamalujTrojuhelnik(...); ... end.
Opět bychom ale museli řeąit otázku, jak schovat jednou namalovaný graf, jak jej začelnit do publikace či jen tak vytisknout na papír.
Nejjednoduąąí by mohlo být poznamenat si, jaké procedury, s jakými parametry a v jakém pořadí, voláme, a v případě potřeby, pak tato volání zopakovat. Nemůľeme se ale spolehnout, ľe příątě bude naąe výstupní medium mít stejné rozliąení. To pro obrazovku činí zhruba jeden megapixel, zatímco při tisku na papír A4 jde o desítky megapixelů. Náą záznam o malování by měl být vůči takovým změnám imunní. Právě proto místo povelů "obarvi puntík [241,1104] na modro" si musíme poznamenat něco jako na souřadnice 241,1104 namaluj kolečko o průměru 1. Takový příkaz lze splnit na obrazovce i na papíře, v jendom případě vystačíme s jedním pixlíkem, v druhém půje o stovky kapiček inkoustu. Terminologie: mluvíme v tomoto případě o vektorové grafice. Její základní vlastností je, ľe na kvalitnějąím zařízení obdrľíme lepąí výsledky, jemnějąí čáry, kulatějąí křivky. Oproti tomu grafika zaloľená na matici bodů nám na lepąím zařízení dá jen lépe propracované čtverečky, pokud nezvětąíme rozměry matice, ale pak půjde jiľ o jiná data. U vektorové grafiky půje dpokaľdé o tentýľ příkaz NamalujKřivku.
Jaký formát vektorové grafiky přesně zvolit za nás uľ vyřeąili a to tentokrát v komerční sféře. A protoľe to udělali velmi dobře, vznikl standard grafického jazyka Postscript (R). Tak, jako jsme si zvykli, ľe program je nejlépe zapsat v textové podobě v nějakém jazyce a před jeho provedením na nějakém počítači si jej necháme přeloľit, i u obrázku budeme mít jednu universální textovou podobu (postscriptový soubor). Pokud budeme chtít získat výsledek na papíře, můľeme se spolehnout, ľe kaľdá lepąí tiskárna soubor správně pochopí, pokud si jej budme chtít prohlédnout na obrazovce počítače, na kaľdé myslitelné platformě (prozatím snad s výjimkou herních konzolí a mobilních telefonů) najdeme zdarma dostupný prohlíľeč obvykle s názvem odvozemým ze slova GhostScript.
Čáry, ploąky, barvy
Předevąím, postscriptový obrázek je program. Na rozíl od Pascalu tento jazyk nerozliąuje deklarační výkonné části (protoľe, jak z časových důvodů neuvidíme, deklarace je v něm také příkazem), a tak ve své nejjednouąąí podobě (jaká nám bude muset stačit) máme jen sérii volání procedur:
%priklad 1 newpath 100 100 moveto 500 800 lineto 450 800 lineto stroke showpage |
 |
Zde vidíme základní principy. Předevąím identifikátor procedury nepředchází parametry, jak je tomu v Pascalu. Naopak, vąechna čísla, která napíąeme, uloľí vykladač jazyka Poscscript na zásobník a odtud si je procedura (řekněmě lineto) vyzvedne.
Vzhledem ke způsobu předávání parametrů
na zásobníku jsou totoľné následující kusy kódu:
A: "100 100 moveto 500 800 lineto"
B: "500 800 100 100 moveto lineto"
Z hlediska grafických operací vidíme, ľe za účelem co největąí universálnosti je proces malování trochu neobvyklý. Zkonstruujeme cestu (path) a to tak, ľe někde začne (moveto) pak pokračuje čarami (lineto) a, kdyľ jsme s cestou hotovi, cestu obtáhneme (stroke) nebo
%priklad 2 newpath 100 100 moveto 500 800 lineto 450 800 lineto fill showpage |
 |
vybarvíme (fill). Cesta je před obtaľením nebo vybarvením neviditlený objekt.
Zde vidíme, ľe z nějakých důvodů zvolili autoři jednotky tak, ľe na palec máme 72 bodů (formát A4 na výąku tak poskytuje k malování plochu [0-595]x[0-842] "bodů"). Slovo bod je zde názvem jednotky, dvaasedmdesátiny palce, nikoli jednotkou rozliąení. U běľných tiskových zařízení se totiľ fyzické rozliąení pohybuje v desítkách pixelů na bod a proto samozřejmě můľeme pouľívat přesnějąí polohu zadáním desetinných míst u čísel.
100.001 200.002 moveto
Druhou moľností bude (viz dále) změnit měřítko a vystačit si s celočíselnými souřadnicemi, řekněme, v mikrometrech.
Barvy
Na počátku se předpokládá, ľe budeme malovat ve stupních ąedi. To znamená, ľe u kaľdého malovaného objektu můľeme nastavovat jeho jas a to voláním procedury setcolor s jedním reálným parametrem (0 = černá, 1 = bílá).
0.45 setcolor
Pokud chceme vytvářet barevný obrázek, musíme to oznámit zavoláním procedury setcolorspace se speciálním parametrem
/DeviceRGB setcolorspace
a od té chvíle nastavujeme barvu zavoláním procedury setcolor
se třemi parametry
%priklad 3 /DeviceRGB setcolorspace 40 setlinewidth 1 0.5 0 setcolor newpath 400 100 moveto 100 400 lineto 100 100 lineto 400 100 lineto stroke 0 0.5 0 setcolor newpath 500 100 moveto 100 500 lineto 500 500 lineto 500 100 lineto closepath stroke showpage |
 |
Vąiměte si na obrázku, ľe uzavření cesty
procedurou closepath změní způsob, jímľ jsou
úsečky pospojovány. Proto je rozdíl, jestli namalujeme tři
úsečky nebo lomenou cestu za tří úseček. Kromě toho, pokud
jsou různé, closepath spojí konec a počátek
aktuální cesty úsečkou.
Grafický stav
Na výąe uvedených příkladech vidíme, ľe
Mimo jiné je součástí grafického stavu
Princip grafického stavu má svůj původ jiľ u souřadnicových zapisovačů, kde se barva měnila výměnou malovacího pera, a běľná poloha byla opravdu polohou pera nad papírem. Pro nás znamená existence grafického stavu, ľe vystačíme s jedinou procedurou stroke pro malování čáry, a» uľ je barevná, čárkovaná, rovná nebo křivá.
Cvičení: Měňte barvy
Cvičení: Vynechte přepnutí do barevného módu a změňte počet parametrů u vąech volání procedury setcolor tak aby měly jeden parametr (0.0 = černá,1.0 = bílá).
Cvičení pro zvídavé: Přidejte do příkladů 1 a 3 před
newpath příkaz
[30 30 160 30] 0 setdash
a pozorujte co se stane (první parametr je typu pole, proto ty
hranaté závorky, druhý parametr je reálné číslo).
Příkazem setcolor se mění nenávratně barva
jíľ malujeme, podobně newpath nenávratně ničí
dosavadní cestu. Protoľe barva i aktuální cesta jsou
součástí grafického stavu, můľeme si je schovat pomocí
procedury gsave, která na
vnitřní zásobník (jiný, neľ ten pro předávání paramtrů
procedurám) uloľí kompletní grafický stav. Nyní můľeme
dle potřeby měnit barvu, měřítka, aktuální polohu atd.a
aľ skončíme, obnovíme původní grafický stav zavoláním
procedury grestore.
Transformace souřadnic
Prozatím jsme respektovali, ľe počátek souřadnic se
nachází vlevo dole, a ľe jednotkou jsou "body".
Následujícími příkazy změníme nejprve měřítko z bodů
na milimetry a poté si posuneme počátek do prostřed strany A4
( 72 bodu na palec / 25.4 milimetrů na palec= 2.8346...bodu na
milimetr ):
2.8346 2.8346 scale
105 148.5 translate
Obecně příkaz
x y translate
posune počátek na uvedenou polohu [x,y], podobně
uhel rotate
pootočí osy o daný úhel, a
meritko_x meritko_y scale
změní měřítka, ne nezbytně na obou osách stejně.
Následující příklad je ilustrací výąe uvedených
operací, tedy schovánání grafického stavu, rotací, posunů
a ąkálování.
%priklad 4 2.8346 2.8346 scale 105 148.5 translate newpath 0 0 moveto gsave 20 0 lineto stroke grestore gsave 30 rotate 2 2 scale 20 0 lineto stroke grestore gsave 60 rotate 3 3 scale 20 0 lineto stroke grestore gsave 90 rotate 3 3 scale 20 0 lineto stroke grestore showpage |
 |
Cvičení: Napiąte program v Pascalu, který namalujte (tedy vytvoří postscripový soubor, který se vykreslí jako) ony kompletní n-úhelníky z minulé přednáąky.
Poznámka: Operacemi moveto lineto lineto moveto linet
Křivky
V praxi bychom neměli pouľívat cestu sloľenou ze stovek kousků. Pokud jde o malování plných čar vystačíme s jejím rozloľením na více kratąích cest (aľ na artefakty při napojování, které jsou vidět u tlustých čar, viz Příklad 3). Pokud je cesta obzvláą» křivá a na její konstrukci bychom potřebovali přílią mnoho úseček tak, aby nebyla viditelně polámaná, máme k dispozici proceduru na malování křivky curveto. Ta maluje parametrickou křivku [x(t),y(t)], kde funkce x(t) a y(t) jsou jsou kubické polynomy. (Mimochodem, úsečka je také takovou parametrickou křivkou, ale polynomy jsou jen prvního stupně.)
| x(t) = x0+3 (x1-x0)
t + 3(x2-2 x1+x0) t^2 + (x3- x0+3
x1-3 x2) t^3 y(t) = y0+3 (y1-y0) t + 3(y2-2 y1+y0) t^2 + (y3- y0+3 y1-3 y2) t^3 |
Vzorečky (C) Bezier |
 |
Obrázek (C) Adobe |
Třetí stupeň byl zvolen proto, aby si člověk mohl zvolit
nejen počáteční a koncový bod křivky (na to stačí
úsečka - první stupeň), ale také tečny v obou koncových
bodech (viz obrázek). To ľe tečný vektor[dx(t)/dt,dy(t)/dt] v
bodě [x0,y0] (tedy v t=0 ) míři do bodu [x1,y1] se z derivace
výąe uvedených polynomů v t=0 pozná snadno. O něco méně
je vidět, ľe v hodnotě parametru t=1, je [x(t),y(t)]=[x3,y3],
a jeąte skrytějąí je fakt, ľe tečna míří z [x3,y3] do
bodu [x2,y2].
Pro nás nejjednoduąąí pouľití curveto
je prosté proloľení křivky čtyřmi body, A,B,C a D. Budeme
poľadovat aby v hodnotě parametru t=0 křivka procházela bodem
A, v hodnotě t=1/3 bodem B, v hodnotě t=2/3 bodem C, v hodnotě
t=1 bodem D. Tak dostaneme soustavu čtyř lineárních rovnic
x(0/3) = Ax
x(1/3) = Bx
x(2/3) = Cx
x(3/3) = Dx
pro čtyři neznámé x0,x1,x2,x3 (nacházející se ve funkci
x(t)) a daląí, nezávislou soustavu čtyř rovnic pro čtyři
neznámé y0,y1,y2,y3. Její řeąení je
| x0 = Ax x1 = (18*Bx-5*Ax+2*Dx-9*Cx)/6 x2 = (2*Ax-5*Dx+18*Cx-9*Bx)/6 x3 = Dx |
y0 = Ay y1 = (18*By-5*Ay+2*Dy-9*Cy)/6 y2 = (2*Ay-5*Dy+18*Cy-9*By)/6 y3 = Dy |
Následující obrázek ilustruje, jak dobrou aproximací
skutečné křivky mohou tyto kubické křivky být.

Červená křivka je čtvtkruľnice. Modrá je výsledek curveto
s parametry podle výąe uvedených vzorečků. Zelené
krouľky vyznačují polohu boudů A.B,C a D a odpovídají
středovému úhlu kruhového oblouku 0,30,60 a 90 stupňů.
Příklad
Kdyľ uľ mluíme o parametrických křivkách, nelze vynechat zmínku o těch nejznámějąích, Lissajousových obrazcích. Zde je program, který je za nás namaluje
program LissaPS;
{
Maluje Lissajousovy obrazce
Umí je malovat čarou nebo vyplnit
Postscriptový obrázek vypíąe na standardní výstup
}
const Vybarvit = true;
var AktualniPoloha : record
x,y : real;
OK : boolean;
end;
procedure KusKrivky(Ax,Ay, Bx,By, Cx,Cy, Dx,Dy : real);
{Pouľívá výąe uvedené vzorečky a proloľí body ABCD kubický oblouk}
var x1,y1,x2,y2 : real;
begin
{ nejdriv spocist polohu ridicich bodu }
x1 := (18*Bx-5*Ax+2*Dx-9*Cx)/6.0;
x2 := (2*Ax-5*Dx+18*Cx-9*Bx)/6.0;
y1 := (18*By-5*Ay+2*Dy-9*Cy)/6.0;
y2 := (2*Ay-5*Dy+18*Cy-9*By)/6.0;
{ na pocatku cesty musi byt newpath & moveto }
if (not AktualniPoloha.OK) then Writeln('newpath');
if (not AktualniPoloha.OK) or (AktualniPoloha.x<>Ax) or (AktualniPoloha.y<>Ay)
then Writeln(Ax:4:2,' ',Ay:4:2,' moveto');
{ pokazde pak curveto }
Writeln(x1:4:2,' ',y1:4:2,' ',x2:4:2,' ',y2:4:2,' ',Dx:4:2,' ',Dy:4:2,' ',' curveto');
AktualniPoloha.x := Dx;
AktualniPoloha.y := Dy;
AktualniPoloha.OK:= true;
end;
procedure Obtahni;
begin
Writeln('stroke');
AktualniPoloha.OK:= false;
end;
procedure Vybarvi;
begin
Writeln('fill');
AktualniPoloha.OK:= false;
end;
procedure Lissajous(sx, sy, Polomer, fazex,fazey : real; kx,ky:integer);
{[sx,sy] je stred, faze* jsou faze obou harm. oscilatací ve stupních}
var i : integer;
N : integer;
Ax,Ay,Bx,By,Cx,Cy,Dx,Dy : real;
function x(m:integer) :real; begin x:=sx+Polomer*sin(fazex+2*Pi/N*kx*(i+m/3.0)); end;
function y(m:integer) :real; begin y:=sy+Polomer*sin(fazey+2*Pi/N*ky*(i+m/3.0)); end;
begin
N := kx; if N<ky then N:=ky;
N := N*8; {videli jsme, ze 4 staci na kruznici}
fazex := fazex*Pi/180.0/kx;
fazey := fazey*Pi/180.0/ky; {uz jsou v radianech}
for i := 0 to N-1 do begin
KusKrivky(
x(0),y(0), {pocatecni bod krivky}
x(1), y(1), { t = 1/3 }
x(2), y(2), { t = 2/3 }
x(3), y(3) {koncovy bod oblouku krivky}
);
end;
if Vybarvit then Vybarvi else Obtahni;
Writeln;
end;
Procedure SetColor(r,g,b:byte); {R G B v rozsahu 0..255}
begin
Writeln(r/255.0:6:3,g/255.0:6:3,b/255.0:6:3,' setcolor');
end;
const R = 50; {polomer v milimetrech}
begin
Writeln('/DeviceRGB setcolorspace');
Writeln('2.8346 2.8346 scale'); {milimetry}
Writeln('105 148.5 translate'); {do stredu A4}
Writeln('0.1 setlinewidth'); {tenke cary}
SetColor(255,174,17);
Lissajous(-R,R, 40, 0,0, 1,2);
SetColor(155,0,0);
Lissajous(R,R, 40, 0,0, 3,4);
SetColor(130,0,130);
Lissajous(-R,-R, 40, 0,0, 7,8);
SetColor(11,80,50);
Lissajous(R,-R, 40, 10,0, 15,16);
Writeln('showpage');
end.
Výstup tohoto programu je potřeba přesměrovat do souboru,
a ten si poté můľeme prohlédnout, vytisknout či poslat
emailem.
| C:\Adresar>LissaPS>obr.ps C:\Adresar>start obr.ps C:\Adresar> |
Příkaz start nám spustí ten program,
který má v počítači na starosti postscriptové obrázkya pak
uvidíme:
 .
.
a nebo

Cvičení: Upravte program tak, aby místo křivek pouľíval lomenou čáru. Pouľít můľete následující proceduru
procedure Lomenice(Ax,Ay, Bx,By, Cx,Cy, Dx,Dy : real);
begin
{ na pocatku cesty musi byt newpath & moveto }
if (not AktualniPoloha.OK) then Writeln('newpath');
if (not AktualniPoloha.OK) or (AktualniPoloha.x<>Ax) or (AktualniPoloha.y<>Ay)
then Writeln(Ax:4:2,' ',Ay:4:2,' moveto');
{ pokazde pak 3x lineto }
Writeln(Bx:4:2,' ',By:4:2,' lineto ',Cx:4:2,' ',Cy:4:2,' lineto ',Dx:4:2,' ',Dy:4:2,' ',' lineto');
AktualniPoloha.x := Dx;
AktualniPoloha.y := Dy;
AktualniPoloha.OK:= true;
end;
Výsledek by pak měl vypadat takto:

Poznámky pro ľivot a ne zkouąku:
Jazyk Postscript vziknul jako jazyk pro ovládání počítačových tiskáren a proto je největąím odborníkem na písmenka. Protoľe můľe být někdy uľitečné doplnit do obrázku pár písmenek, je v následujícím příkladě shrnuto několik nejpotřebnějąích procedur pro práci s textem.
%priklad 5 (Helvetica) 40 selectfont 300 420 moveto (ABC) show (123) show showpage |
 |
Vidíme, ľe
Procedura selectfont má za první parametr název písma,
druhý je jeho velikost.
Vľdy k dispozici by (mimo jiné) měla být následující
písma:

Vypadá to, ľe bychom uľ měli o jazyce postscript vědět
to nejpodstatnějąí. Třeba bychom si mohli myslet, ľe kdyľ
si budme prohlíľet postscriptový soubor narazíme na série
příkazů 213 321 moveto 545 545 lineto 45 544 moveto 577
889 lineto 54 889 lineto ....
Kdyľ ale nějaký otevřeme v textovém editou, zjistíme, ľe
na počátku nejsou skoro ľádná čísla, takľe se tam dost
dobře nemohou malovat přísluąné křivky, na konci zase
narazíme na spousti čísel a skoro ľádná písmena.
Vysvětlení je jednoduché. Postscritpt je programovací jazyk.
Proto na začátku narazíme na oblast definic procedur a
funkcí, tzv. prolog, na konci se pak tyto funkce pouľívají.
Proto program který má v úmyslu malovat spoustu
trojúhelníků nejprve definuje proceduru pro malování
trojúhelníků, a pak uľ pouľívá ji místo neustálého newpath,
moveto ...
%priklad X
/t {
newpath
moveto
lineto
lineto
fill
} def
100 100 300 100 100 300 t
200 200 400 200 200 400 t
300 300 500 300 300 500 t
showpage
|
 |
Programu nejlépe porozumíme, přeloľíme-li si začátek podle tabulky
| /t { | ---> | procedure t; begin |
| } def | ---> | end; |
a uvědomíme-li si, ľe procedury moveto, lineto a jeątě jednou lineto vyzvednou ze zásobníku kaľdá dva parametry. Pak je zřejmé, ľe procedura t jich potřebuje ąest.
Zájemce o daląí informace o jazyce Postscript můľe pouľít dokumenty, které firma Adobe dává volně k dipozici, předevąím pak učebnici, kterou lze vygooglovat dotazem "postscript bluebook pdf" (240 stran), případně referenční příručku ("postscript PLRM pdf", 912 stran).
Konec poznámek pro ľivot a ne zkouąku.
Jeątě k vyhodnocování výrazů
Kdyľ napíąeme a+b*c je zřejmé, kolik má být výsledek. Pokud ale a, b nebo c jsou funkce, můľe být kromě výsledku důleľité i pořadí, v němľ se funkce volají. Pokud potřebujeme zaručit dodrľení nějakého konkrétního pořadí, je nejjednoduąąí nějdříve provést sérii přiřazovacích příkazů a pak teprve spočíst výraz:
a1 := a;
b1 := b;
c1 := c;
X := a1+b1*c1;
Shrnutí: pozor na postranní efekty funkcí
volaných ve výrazech.
Neúplné vyhodnocování logických výrazů
U logických výrazů nastává zajímavý jev: počítáme-li hodnotu logického výrazu, řekněme
(a > 0) and (b-a > n)
tak pro a<=0 rovnou víme, ľe výsledek je FALSE a» uľ je hodnota b jakákoli. Neúplné vyhodnocování logických výrazů je metoda překladu logických výrazů, kdy jakmile je jasný výsledek logického výrazu při jeho vyhodnocování zleva doprava, vyhodnocování se ukončí. To má několik pouľití:
if (a<>0) and (b/a-c>0) then ...
takto předřazením testu na dělení nulou zabráníme vlastnímu dělení, protoľe a=0 znamená, ľe výsledek je FALSE a» uľ je b a c jakékoli.
if JeToZena(C) or MaVPoradkuOhryzek(C) then
můľe v programu pro zdravodtní pojiątovny kontrolovat ...., aniľ se dopustíme nedovoleného dotazu na zdravotní stav neexistující části pacientek, obzváątě je-li přísluąná informace uloľena např. ve variantním záznamu a tak není vůbec definována.
Pozn.: Pokud se najde opravdu dobrý důvod, lze si úplné vyhodnocování vynutit zapnutím {$BOOLEVAL ON}.
Skoky
Strukturované programování mělo za cíl učinit příkaz skoku aľ na výjimky zbytečným. Tento svůj cíl splnilo, protoľe jsme jej doposud na přednáące nepotřebovali. Přesto existují situace, kdy je jejich pouľití na místě. K dipozici máme následující příkazy skoku:
| break | ukončí průběh cyklů for, repeat a while | |
| continue | vrací na začátek daląího cyklu | |
| exit | ukončí běh procedury nebo funkce | |
| halt | ukončí běh programu | |
| goto | skočí na určené návěątí (pouze v daném bloku) |
Příklady:
program pLabel; label L; begin L: goto L; end.
Dále
for i :=Low(data)+1 to High(data) do if data[i-1]>data[i] then writeln('NESETRIDENO !');
z příkladu na třídění bychom spíą měli nahradit
for i :=Low(data)+1 to High(data) do if data[i-1]>data[i] then begin writeln('NESETRIDENO !'); break; end;
aby se varování vypsalo jej jednou. Podobně procedura pro nalezení poloľky v seznamu můľe vyuľít exit.
program Test;
function JeVSeznamu(const S:array of integer; n : integer) : boolean;
var i: integer;
begin
JeVSeznamu := true;
for i := low(S) to High(S) do
if S[i] = n then exit;
JeVSeznamu := false;
end;
begin
Writeln( JeVSeznamu([12,5,44,69,2,5,3,44,58,56,4],3) );
Readln;
end.
Ladění
Základním postupem při ladění je vloľení ladících výpisů do programu. Program tak vypisuje, co zrovna dělá (kde je) a jaké hodnoty mají klíčové proměnné. Do místa, kde se výpisy rozcházejí s očekáváním vloľíme daląí podrobnějąí výpisy, aľ lokalizujeme zdroj problému.
Moderní vývojové prostředky umoľňují sledovat činnost
programu krok za krokem. Přesněji můľeme pozastavit běh
programu
- na daląím řádku se vstupem do procedur (F7)
- na daląím řádku bez vstupu do procedur (F8)
- na určeném řádku (breakpoint trvalý F5 a dočasný F4)
- po návratu z procedury (Shif-F8)
Při pozastavení programu můľeme kontrolovat hodnotu výrazů a to buď jednorázově (Ctrl-F7) nebo je můľeme zařadit do seznmu sledovaných výrazů (Ctrl-F5), hodnotu proměnných můľeme dokoce měnit a třeba zkusit, zda tak napravíme co nějaká chyba poąkodila....
Ilustrace: hledáme nějakou chybu
Pozor: Kdyľ to nechodí zkusíme nejdříve zapnout {$R+,Q+}
a přidat uses sysutils.
Parametr typu procedura a funkce
Předpokládejme, ľe píąeme modul pro tříděni. Řekněme, ľe jiľ víme, jaký algoritmus pouľít i jak psát modul. Kdyľ ale začneme psát, zjistíme, ľe nám něco chybí - moľnost napsat modul tak, aby nemusel vědět jaká data vlastně třídí, případně aby mohla tatáľ procedura třídit seznamy různých typů. To proto, ľe kdyľ chce procedura pracovat s nějakými daty, musí v Pascalu znát jejich typ.
Jedním z řeąení je předpokládat, ľe ten, kdo bude chtít třídit, místo dat poąle proceduře pro třídění jako parametry něco jiného neľ samotná data. Třeba jen odkaz na procedury, jednu která porovná j-tý a k-tý prvek a druhou, co je na poľádání přehodí.
Zde je přísluąný modul:
unit Tridicka;
interface
type tPorovnaciFunkce = function( j,k : integer ) : integer;
tPrehazovaciProcedura = procedure( j,k : integer );
procedure Setrid(Porovnej:tPorovnaciFunkce; Prehod:tPrehazovaciProcedura;l,r:integer);
implementation
procedure Setrid(Porovnej:tPorovnaciFunkce; Prehod:tPrehazovaciProcedura;l,r:integer);
var i, j, k_rozhod : Integer;
begin
k_rozhod := (l + r) div 2;
i := l; j := r;
while i<j do begin
while Porovnej(i,k_rozhod)<0 do i:=i+1;
while Porovnej(k_rozhod,j)<0 do j:=j-1;
if i <= j then begin
Prehod(i,j);
if i=k_rozhod then k_rozhod:=j
else if j=k_rozhod then k_rozhod:=i;
i:=i+1; j:=j-1;
end;
end;
if l < j then Setrid(Porovnej, Prehod, l, j);
if i < r then Setrid(Porovnej, Prehod, i, r);
end;
end.
A zde je program, který modul pouľívá k setřídění pole reálných čísel.
program tridtest;
uses Tridicka;
var Data : array [0..220000] of real;
function PorovnejData( i,j : integer ) : integer;
{musi se shodovat s type tPorovnaciFunkce = function( j,k : integer ) : integer;}
begin
if Data[i]<Data[j] then PorovnejData := -1
else if Data[i]=Data[j] then PorovnejData := 0
else PorovnejData := +1;
end;
procedure PrehodData( i,j : integer );
{musi se shodovat s type tPrehazovaciProcedura = procedure( j,k : integer );}
var s : real;
begin
s := Data[i];
Data[i] := Data[j];
Data[j] := s;
end;
var i : integer;
begin
for i :=Low(data) to High(data) do data[i]:=random;
Setrid(PorovnejData, PrehodData, Low(Data) , High(data) );
for i :=Low(data)+1 to High(data) do if data[i-1]>data[i] then writeln('NESETRIDENO !');
Writeln('OK');
readln;
end.
Těľiątě příkladu je na řádcích obsahujících slovo Setrid
deklarace: procedure Setrid(Porovnej:tPorovnaciFunkce; Prehod:tPrehazovaciProcedura;l,r:integer); volání: Setrid(PorovnejData, PrehodData, Low(Data) , High(data) );
a v deklaraci typů
type tPorovnaciFunkce = function( j,k : integer ) : integer;
tPrehazovaciProcedura = procedure( j,k : integer );
kde překladači sdělujeme, ľe se má naučit tyto dva typy, nebo» je pouľijeme jako typy formálního argumnetu. Vąimnětě si, ľe typy se liąí od deklarace procedury či funkce jen vynecháním jejícho identifikátoru. Protoľe je formální parametr Porovnej deklarován s typem tProvnavaciFunkce, ví překladač, co má udělat, kdyľ narazí na výraz
Porovnej(i,k_rozhod)
Ilustrace (na přednáące) : krokování programem, ladění
Cvičení: Změňte výąe uvedený program tak aby generoval
pole 20 náhodných komplexních čísel a pak jej vytiskněnte
seřazené podle
a) hodnoty reálné části
b) hodnoty imaginární části
c) velikosti
d) argumentu
Modul Tridicka samozrejme nemente!
Soubory stejných záznamů
Jiľ jste si asi vąimli, ľe v posledních letech umoľnil růst výkonu počítačů uchovávat v textové podobě kdejaká data, např. elektronickou poątou (tedy sí»ovým protokolem pro přenos textového dokumentu) dokáľete přenést (a poté uchovat) nejen "Ahoj Honzo" ale i obrázky, archivy, viry...
Mnohé soubory ve vaąem počítači ale nejsou textové.
Někdy se pouľívají pro uloľení mnoha stejných poloľek soubory vzniklé záznamem jednotlivých poloľek tak, jak jsou uloľeny v paměti, za sebou do souboru. Budeme-li chtít realizovat velmi dlouhou strukturu typu fronta, můľeme ji kromě paměti uloľit realizovat i na disku. K tomu pouľijeme soubor sloľený z libovolného počtu stejných záznamů. To Pascalu oznámíme deklarací typu
file of Typ_polozky
s proměnnými, tedy vlastně soubory, tohoto typu pak pracujeme pomocí procedur
| Assign | přiřazení jména souboru | |
| Rewrite | Vytvoření nebo zkrácení na nulovou délku + otevření souboru pro četní i zápis |
|
| Reset | Otevření existujícího + otevření souboru pro četní i zápis | |
| Read | Přečtení poloľky | |
| Write | Zápis poloľky | |
| Seek | Přesunutí polohy pro čtení a zápis na danou poloľku |
S těmito informacemi můľeme jiľ pochopit následující program:
program FrontaVSouboru;
type tZaznam = record
Jmeno : string[20];{!!! nesmi tam byt jen string !!!}
PolozkaA,
PolozkaB,
PolozkaC : integer;
end;
{Fronta v souboru:}
var frSoubor : file of tZaznam;
frZacatek,
frKonec : integer;
{Operace:}
Procedure frZacni;
begin
Assign(frSoubor,'Fronta.tmp');
Rewrite(frSoubor);
end;
procedure frVloz(const X: tZaznam);
begin
Seek(frSoubor,frKonec);
frKonec:=frKonec+1;
Write(frSoubor,X);
end;
function frVyber(var X: tZaznam): boolean;
begin
frVyber := false;
if (frZacatek<frKonec) then begin
Seek(frSoubor,frZacatek);
frZacatek:=frZacatek+1;
Read(frSoubor,X);
frVyber := true;
end;
end;
Procedure frSkonci;
begin
Close(frSoubor);
end;
var X : tZaznam;
begin
frZacni;
X.Jmeno := 'Polozka 1'; frVloz(X);
X.Jmeno := 'Polozka 2'; frVloz(X);
if frVyber(X) then Writeln(X.Jmeno);
X.Jmeno := 'Polozka 3'; frVloz(X);
if frVyber(X) then Writeln(X.Jmeno);
X.Jmeno := 'Polozka 4'; frVloz(X);
X.Jmeno := 'Polozka 5'; frVloz(X);
while frVyber(X) do Writeln(X.Jmeno);
frSkonci;
readln;
end.
Velký pozor ! V případě, ľe pouľíváme tento druh práce se soubory, musíme si být jisti, ľe v poloľce jsou opravdu uloľena data, která chceme zapsat na disk. Uvaľujme následující program:
program Zrada;
type tZaznam = record
Jmeno : string;
end;
var X : tZaznam;
begin
X.Jmeno := 'Velmi dlouhe jmeno (mozna jeste delsi)';
Writeln(X.Jmeno);
Writeln(sizeof(X));
readln;
end.
Velmi nás překvapí, ľe velikost proměnné X jsou pouhé 4 byte. Důvod je prostý, řetězce typu string jsou jistou variantou dynamických polí a vlastní proměná je jen odkazem, kde má program hledat m.j. délku řetězce (délku pole), a znaky řetězce (prvky pole). Uloľením tohoto údaje do souboru bychom si uloľili pomíjivou (meta-) informaci, ale nikoli potřebná data.
Proto musí být součástí poloľek záznamů, ze kterých vytváľíme (otypovaný) soubor konstrukcí file of tPolozka, jen typy, jejichľ velikost je neměnná, např:
Jednoduché typy ( integer, real, boolean, ...)
Pole s uvedenými mezemi ( array [1..N] of ... )
Řetězce s danou délkou ( string[255] ...)
I kdyľ budeme dodrľovat tato pravidla, mohou nastat potíľe, pokud přenáąíme soubory a program, který s nimi pracuje, mezi počítači odliąných architektur (pozor na endiány) a nebo pouľíváme různé kompilátory jazyka Pascal (ve starąích verzích byl integer je 16-ti bitové číslo, v příątích nás nemine 64 bitů).
Pozn.: Myslím, ľe pouľití otypovaných souborů je velmi omezené
Binární soubory
Metoda Udělěj si sám, není optimální strategií pro tvorbu sloľitějąího programu. Víme, ľe nalezení dobrého algoritmu dá práci, a víme, ľe se vyplatí pouľít hotový modul, pokud implemetuje dobrý algoritmus a je v něm méně chyb, neľ v novorozeném programu. Podobně jsme zjistili, ľe spíąe, neľ bychom se snaľli poroučet inkoustovým kapičkám, chceme-li v nejvyąąí kvalitě malovat na papír hezké obrázky, pouľijeme dobře definovaný jazyk pro popis obrázků (Postscript). To bylo obzvláą» jednoduché, protoľe postscriptový soubor byl běľný textový soubor.
Často se ale stává, ľe dohodnutý formát pro uloľení toho, či onoho druhu dat má podobu řady bytů, a nikoli textu. Takovému souboru říkáme binární.
Jako příklad nám poslouľí nekomprimovaný obrázek. Ten má povahu matice hodnot, které popisují barvu toho kterého bodu matice. Bohuľel nestačí do souboru např. zapsat jen 1200 hodnot barvy, protoľe je jeąte potřeba dodat, zda je to obrázek 30x40 nebo 40x30 nebo 20x60 atp. Proto vlastním datům předchází hlavička, kde je uvedeno vąe, co je potřeba vědět pro správné zobrazení obrázku.
Podrobnosti o struktuře hlavičky, způsobu ukládání barev atp. lze samozřejmě nalézt, my ale pouľijeme trik, který nám umoľní soustředit se na demonstraci práce s binárním souborem a nikoli na detaily vnitřností jednoho primitivního grafického formátu.
Trik bude spočívat v tom, ľe nejdříve pomocí programu pro práci s obrázky vytvoříme prázdný obrázek poľadovaného formátu a velikosti. Program pak bude do nového souboru zapíąe kopii hlavičky původního obrázku a za ní zapíąe svá vlastní data (puntíky obrázku).
program Fraktal;
uses Windows;
const N = 600;
BmpNxX = 'Blank600x600.bmp';
type tPixel = packed record b,g,r:byte; end;
tBmpArr= packed array [1..N,1..N] of tPixel;
procedure WrBmp(const X : tBmpArr; const Name: string);
{Procedura vezme bitmapovy soubor velikosti NxN
a vytvori jeho kopii ale s obrazkem X, (toto je ukazka techniky quick & dirty)}
const NN = 3*N*N+10000;
var A:array of byte; {bohuzel tak velke lokalni pole musi byt dynamicke}
F : file;
Nacteno,VelHlavicky : integer;
begin
SetLength(A,NN);
{1. cteni z binarniho souboru}
Assign(F,BmpNxX);
Reset(F,1);
nacteno := 0;
BlockRead(F,A[0],NN,nacteno);{musi byt A[0] pro dyn. pole !!}
Close(F);
{2. nevim jak presne ma byt velka hlavicka souboru}
VelHlavicky := nacteno-3*N*N;
assert( (VelHlavicky>30) and (VelHlavicky<1000) );
{3. Zapis do souboru}
Assign(F,Name);
Rewrite(F,1);
BlockWrite(F,A[0],VelHlavicky); {Puvodni hlavicka}
BlockWrite(F,X,3*N*N); {Novy obrazek}
Close(F);
end;
type tPixArr = packed array[0..2] of byte;
{$I firestorm.inc}
function Barva(a,b : real):tPixel;
var x,y,x1,x2,y2 : real;
Index,s : integer;
const N = 1;
M = 1;
{Konstanty M a N určují způsob, jímľ se počet iterací z rozsahu 0..256*N
převede do rozsahu indexu barev 0..255.
N=M odpovídá lineárnímu vztahu,
M=1 naopak zachová rozliąení za cenu recyklace barev.}
begin
s:=256*N;
x := 0;
y := 0;
repeat
s:=s-1;
x1 := x; {schovam si to}
x2 := x*x;
y2 := y*y;
x := x2 - y2 + a;
y := 2*x1*y + b;
until (x2+y2>4) or (s=0) ;
Index:=(s div M) mod 256;
Barva.R := ColorMap[Index,0];
Barva.G := ColorMap[Index,1];
Barva.B := ColorMap[Index,2];
end;
var i,j:integer;
X : tBmpArr;
const sx = 0.053;
sy = 0.621; {poloha stredu obrazku}
dxy = 0.05; {velikost obrazku}
begin
{Pro x=-dxy..dxy a y = -dxy..dxy opakuj spocibarvu....}
for i:=1 to N do
for j := 1 to N do
X[j,i] := Barva( (2*i-N)/N*dxy+sx , (2*j-N)/N*dxy+sy );
WrBmp(X,'obr.bmp');
{pozor pod win95 a win98 je potreba pouzit misto cmd.exe prikaz command.com}
WinExec('cmd.exe /C start obr.bmp',1);
end.
Pomocí vkládací direktivy {$I ...} je do programu vloľen
následující soubor s defnicí převodní tabulky
(počet iterací) --> (barva).
{Colormap by Mark Peterson}
const ColorMap : array [0..255] of tPixArr = (
( 0 , 0 , 0 ),( 144 , 10 , 229),(147,9,227),(150,8,225),(153,6,223),(156,6,221),(159,5,218),(162,4,216),(165,3,214),
(168,2,212),(171,2,209),(174,1,207),(177,1,204),(180,1,202),(183,0,199),(186,0,197),(189,0,194),(191,0,191),(194,0,189),(197,0,186),(199,0,183),(202,1,180),
(204,1,177),(207,1,174),(209,2,171),(212,2,168),(214,3,165),(216,4,162),(218,5,159),(221,6,156),(223,6,153),(225,8,150),(227,9,147),(229,10,144),(231,11,141),
(232,12,138),(234,14,135),(236,15,131),(238,17,128),(239,18,125),(241,20,122),(242,22,119),(243,23,116),(245,25,113),(246,27,109),(247,29,106),(248,31,103),
(249,33,100),(250,35,97),(251,38,94),(252,40,91),(252,42,88),(253,45,85),(253,47,82),(254,49,79),(254,52,76),(255,54,73),(255,57,71),(255,60,68),(255,62,65),
(255,65,62),(255,68,60),(255,71,57),(255,73,54),(254,76,52),(254,79,49),(253,82,47),(253,85,45),(252,88,42),(252,91,40),(251,94,38),(250,97,35),(249,100,33),
(248,103,31),(247,106,29),(246,109,27),(245,113,25),(243,116,23),(242,119,22),(241,122,20),(239,125,18),(238,128,17),(236,131,15),(234,135,14),(232,138,12),
(231,141,11),(229,144,10),(227,147,9),(225,150,8),(223,153,6),(221,156,6),(218,159,5),(216,162,4),(214,165,3),(212,168,2),(209,171,2),(207,174,1),(204,177,1),
(202,180,1),(199,183,0),(197,186,0),(194,189,0),(191,191,0),(189,194,0),(186,197,0),(183,199,0),(180,202,1),(177,204,1),(174,207,1),(171,209,2),(168,212,2),
(165,214,3),(162,216,4),(159,218,5),(156,221,6),(153,223,6),(150,225,8),(147,227,9),(144,229,10),(141,231,11),(138,232,12),(135,234,14),(131,236,15),
(128,238,17),(125,239,18),(122,241,20),(119,242,22),(116,243,23),(113,245,25),(109,246,27),(106,247,29),(103,248,31),(100,249,33),(97,250,35),(94,251,38),
(91,252,40),(88,252,42),(85,253,45),(82,253,47),(79,254,49),(76,254,52),(73,255,54),(71,255,57),(68,255,60),(65,255,62),(62,255,65),(60,255,68),(57,255,71),
(54,255,73),(52,254,76),(49,254,79),(47,253,82),(45,253,85),(42,252,88),(40,252,91),(38,251,94),(35,250,97),(33,249,100),(31,248,103),(29,247,106),(27,246,109),
(25,245,113),(23,243,116),(22,242,119),(20,241,122),(18,239,125),(17,238,128),(15,236,131),(14,234,135),(12,232,138),(11,231,141),(10,229,144),(9,227,147),
(8,225,150),(6,223,153),(6,221,156),(5,218,159),(4,216,162),(3,214,165),(2,212,168),(2,209,171),(1,207,174),(1,204,177),(1,202,180),(0,199,183),(0,197,186),
(0,194,189),(0,191,191),(0,189,194),(0,186,197),(0,183,199),(1,180,202),(1,177,204),(1,174,207),(2,171,209),(2,168,212),(3,165,214),(4,162,216),(5,159,218),
(6,156,221),(6,153,223),(8,150,225),(9,147,227),(10,144,229),(11,141,231),(12,138,232),(14,135,234),(15,131,236),(17,128,238),(18,125,239),(20,122,241),
(22,119,242),(23,116,243),(25,113,245),(27,109,246),(29,106,247),(31,103,248),(33,100,249),(35,97,250),(38,94,251),(40,91,252),(42,88,252),(45,85,253),
(47,82,253),(49,79,254),(52,76,254),(54,73,255),(57,71,255),(60,68,255),(62,65,255),(65,62,255),(68,60,255),(71,57,255),(73,54,255),(76,52,254),
(79,49,254),(82,47,253),(85,45,253),(88,42,252),(91,40,252),(94,38,251),(97,35,250),(100,33,249),(103,31,248),(106,29,247),(109,27,246),(113,25,245),
(116,23,243),(119,22,242),(122,20,241),(125,18,239),(128,17,238),(131,15,236),(135,14,234),(138,12,232),(141,11,230)
);
Z hlediska přednáąky je těľiątě programu v proceduře WrBmp, která pouľívá procedury pro čtení z a zápis do binárních souborů. Jak je vidět, operace s binárními soubory se v několika ohledech odliąují od textových i otypovaných souborů.
1. U operací Reset a Rewrite musíme dodat jak velká je základní nedělitelná jednotka dat. Pokud tento údaj zapomeneme uvést, volí ObjectPascal automaticky prehistorickou jednotku o velikosti 128 byte, místo aby si stěľoval !
2. Operace pro čtení se teď jmenuje BlockRead
BlockRead( var BinarniSoubor : file;
var PromennaDoNizChcemeNacistData; KolikJednotek
: integer; var KolikSePovedloNacist : integer)
3. Operace pro psaní se teď jmenuje BlockWrite
BlockWrite( var BinarniSoubor : file;
var PromennaZNizChcemeZapsatData; KolikJednotek
: integer; var KolikSePovedloZapsat : integer)

Cvičení: Změňte v minulém programu rozliąení z 600x600 na víc/míň podle schopností vaąeho počítače. Nezaponeňte program také spustit a vyzkouąet, ľe funguje. Aľ budete vytvářet novou prázdnou bitmapu, zvolte způsob uloľení barev jako barevný, 24-bit (tzv. TrueColor).
Cvičení: Nakreslete rovnostranný trojúhelník barev pro které platí r+g+b=1 (vyuľívá vlastností rovnostranného trojúhelníka, ľe součet vąech třech výąek je konstantní, pro ty, co nemají rádi analytickou geometrii r := y;g := (sqrt(3)*x-y)/2;b := (2-sqrt(3)*x-y)/2, ale jeąte je třeba zkontroovat, ľe jsou vąechny kladné.)

Dynamické datové struktury (poznámky povrchní)
Prozatím jsme se omezili jen na pole s proměnnou délkou, seznamy, fronty a zásobníky. Ve vąech případech jde jen o velmi primitivní dynamické datové struktury.
Viděli jsme, na příkladu procházení souborového
systému, ľe důleľitou datovou strukturou jsou stromy, jako
speciální případy tzv. grafů. (Pozn. při výkladu: Uzly a
hrany grafu). V následujícím programu zavedeme takové typy a
proměnné, ľe v nich dokáľeme uloľit libovolný strom.
(Pozn. při výkladu: Graf v matici
array [tCisloPrvku, tCisloPrvku] of
boolean
a proč ne (obzvláą») u stromu.)
Zavedeme rodokmen hermafroditních organismů. Kaľdý bude mít Jméno a seznam svých potomků. Pomocí vhodně definované funkce umoľníme zapsat strukturu stromu jedním příkazem programu a ukáľeme si práci se stromem pomocí dvou funkcí, první Jmeno2COP převede jméno na identifikační číslo organismu (index v seznmau t.j. pra-ukazatel) a druhá mi pro kaľdého spočte počet potomků jako součet počtu potomků + počtu jejich potomků+....
program DynDa;
type tCOP = integer;
type tUzel = record
Jmeno : string;
Deti : array of tCOP;
end;
var Stromek : record
Prvky : array of tUzel;
Pocet : tCOP;
end;
function X(const NoveJmeno : string; const NoveDeti : array of tCOP): tCOP;
var k : integer;
i : tCOP;
begin
// Sileny trik: necham nulty prvek nastaveny na zadne jmeno, zadne deti
{Nejdříve musím vyrobit NOVOU POLO®KU i}
i := Stromek.Pocet+1;
Stromek.Pocet := i;
if i>High(Stromek.Prvky) then begin SetLength(Stromek.Prvky,10+2*High(Stromek.Prvky)); end;
{Nikdy nezvetsovat po jedne, vzdy geometrickou radou !!!}
X := i;
with Stromek.Prvky[i] do begin
Jmeno := NoveJmeno;
SetLength(Deti,High(NoveDeti)+1);
for k:=Low(NoveDeti) to High(NoveDeti) do Deti[k] := NoveDeti[k];
end;
end;
function Jmeno2COP(const Jmeno:string) : tCOP;
var i : tCOP;
begin
Jmeno2COP := 0;
for i := Low(Stromek.Prvky) to High(Stromek.Prvky) do
if Stromek.Prvky[i].Jmeno = Jmeno then begin
Jmeno2COP := i;
exit;
end;
end;
function PocetPotomku(const COP:tCOP) : integer;
var i,s : integer;
begin
s := 0;
with Stromek.Prvky[COP] do
for i := Low(Deti) to High(Deti) do s:=s+1+PocetPotomku(Deti[i]);
PocetPotomku := s;
end;
var Otec : tCOP;
begin
Otec := X('Petr',[
X('Karel',[
X('Mirek',[]),
X('Zdenek',[])
]),
X('Ivan',[
X('Hugo',[
X('Rudolf',[]),
X('Gustav',[
X('Cecil',[])
]),
X('Klement',[])
])
])
]);
Writeln(PocetPotomku( Jmeno2COP('Ivan') ) );
Readln;
end.
Příklady problémů, které vedou na uloľení dat v podobě stromu.
Cvičení: Napiąte proceduru, která vytiskne rodokmen. Nejjednoduąąí bude rekursivní varianta s parametry COP, a pořadím generace (= počet mezer).
Petr
Karel
Mirek
Zdenek
Ivan
Hugo
Rudolf
Gustav
Cecil
Klement
Případně zksute i sloľitějąí podobu s čárkami
Petr
+ Ivan
| + Hugo
| + Rudolf
| + Gustav
| | - Cecil
| - Klement
- Karel
+ Mirek
- Zdenek